Quick recap

Quick recap

Quick recap

Quick recap
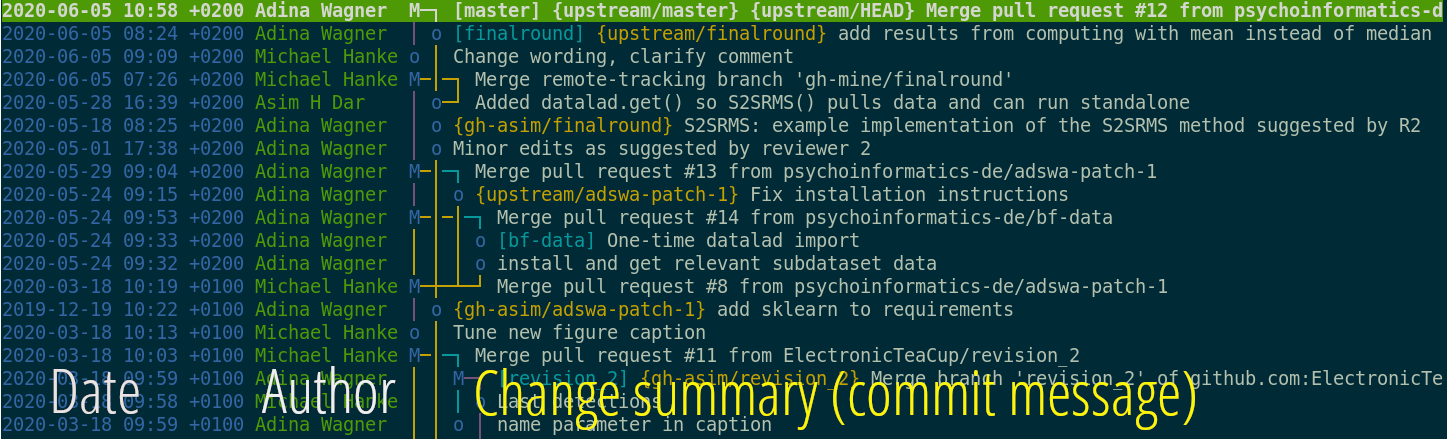
Quick recap

Before we begin...
Any left-over questions from yesterday?Publishing datasets
| How to share your work with others |
Repository hosting services, siblings, and datalad push |
"Share data like source code"
- Datasets can be cloned, pushed, and updated from and to local and remote paths, remote hosting services, external special remotes
- Examples:
Local path
Remote path../my-projects/experiment_data
Hosting servicemyuser@myinstitutes.hcp.system:/home/myuser/my-projects/experiment_data
External special remotesgit.github.com:myuser/experiment_data.gitosf://my-osf-project-id

Interoperability
- DataLad is built to maximize interoperability and use with hosting and storage technology
 See the chapter
Third party infrastructure for walk-throughs for different services
See the chapter
Third party infrastructure for walk-throughs for different services
Interoperability
- DataLad is built to maximize interoperability and use with hosting and storage technology
 See the chapter
Third party infrastructure for walk-throughs for different services
See the chapter
Third party infrastructure for walk-throughs for different services
Publishing datasets
I have a dataset on my computer. How can I share it, or collaborate on it?
Glossary
- Sibling (remote)
- Linked clones of a dataset. You can usually update (from) siblings to keep all your siblings in sync (e.g., ongoing data acquisition stored on experiment compute and backed up on cluster and external hard-drive)
- Repository hosting service
- Webservices to host Git repositories, such as GitHub, GitLab, Bitbucket, Gin, ...
- Third-party storage
- Infrastructure (private/commercial/free/...) that can host data. A "special remote" protocol is used to publish or pull data to and from it
- Publishing datasets
- Pushing dataset contents (Git and/or annex) to a sibling using datalad push
- Updating datasets
- Pulling new changes from a sibling using datalad update --merge
Publishing datasets
- Most public datasets separate content in Git versus git-annex behind the scenes

Publishing datasets

Publishing datasets

Publishing datasets
Typical case:- Datasets are exposed via a private or public repository on a repository hosting service
- Data can't be stored in the repository hosting service, but can be kept in almost any third party storage
-
Publication dependencies automate pushing to the correct place, e.g.,
$ git config --local remote.github.datalad-publish-depends gdrive # or $ datalad siblings add --name origin --url git@git.jugit.fzj.de:adswa/experiment-data.git --publish-depends s3

Publishing datasets
- Real-life example 1:
GitHub for repository hosting, data hosting via datapub.fz-juelich.de + GNODE
Publishing datasets
- Real-life example 2:
GitLab for repository hosting, data hosting via internal webserver (access restricted)
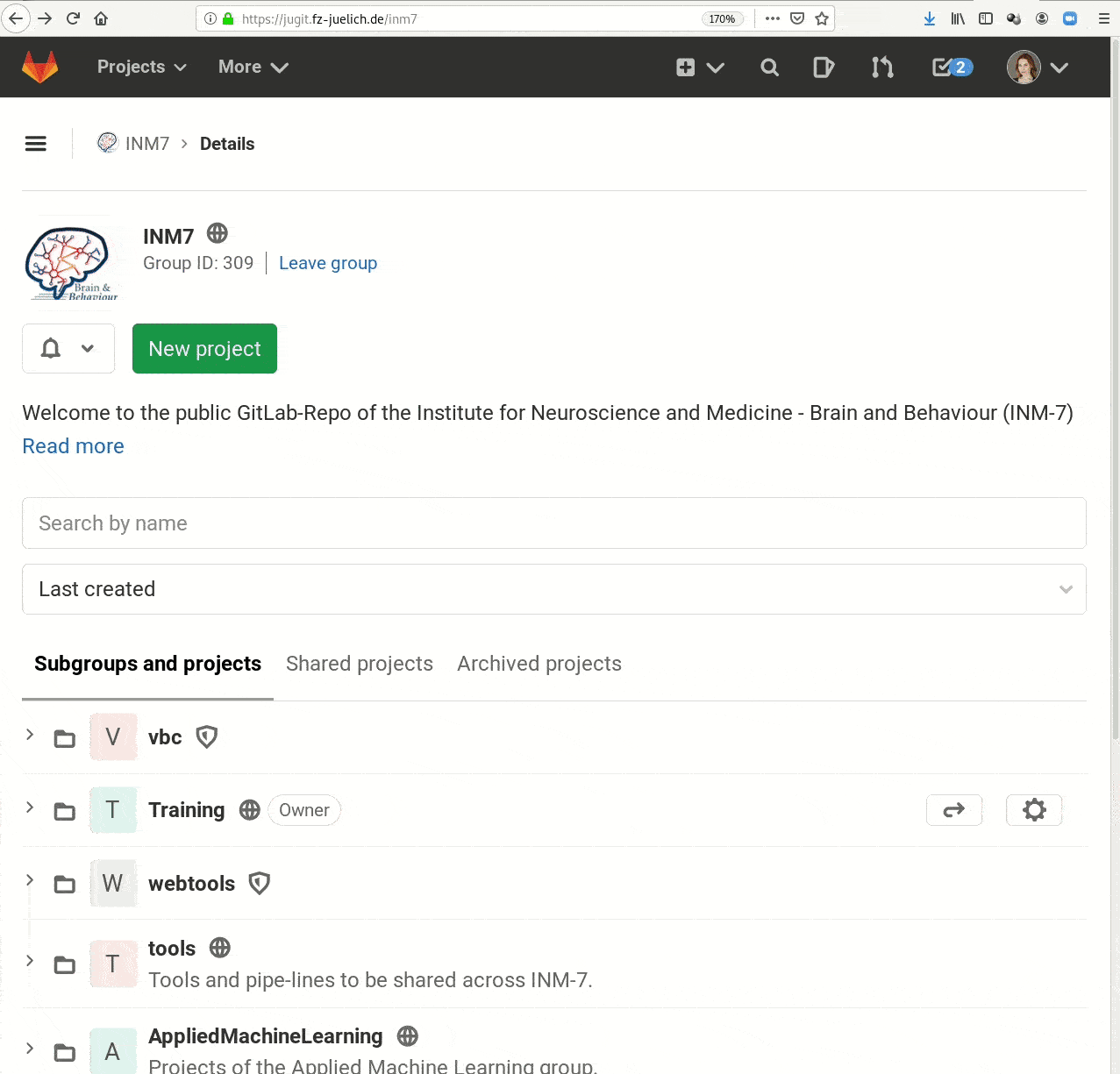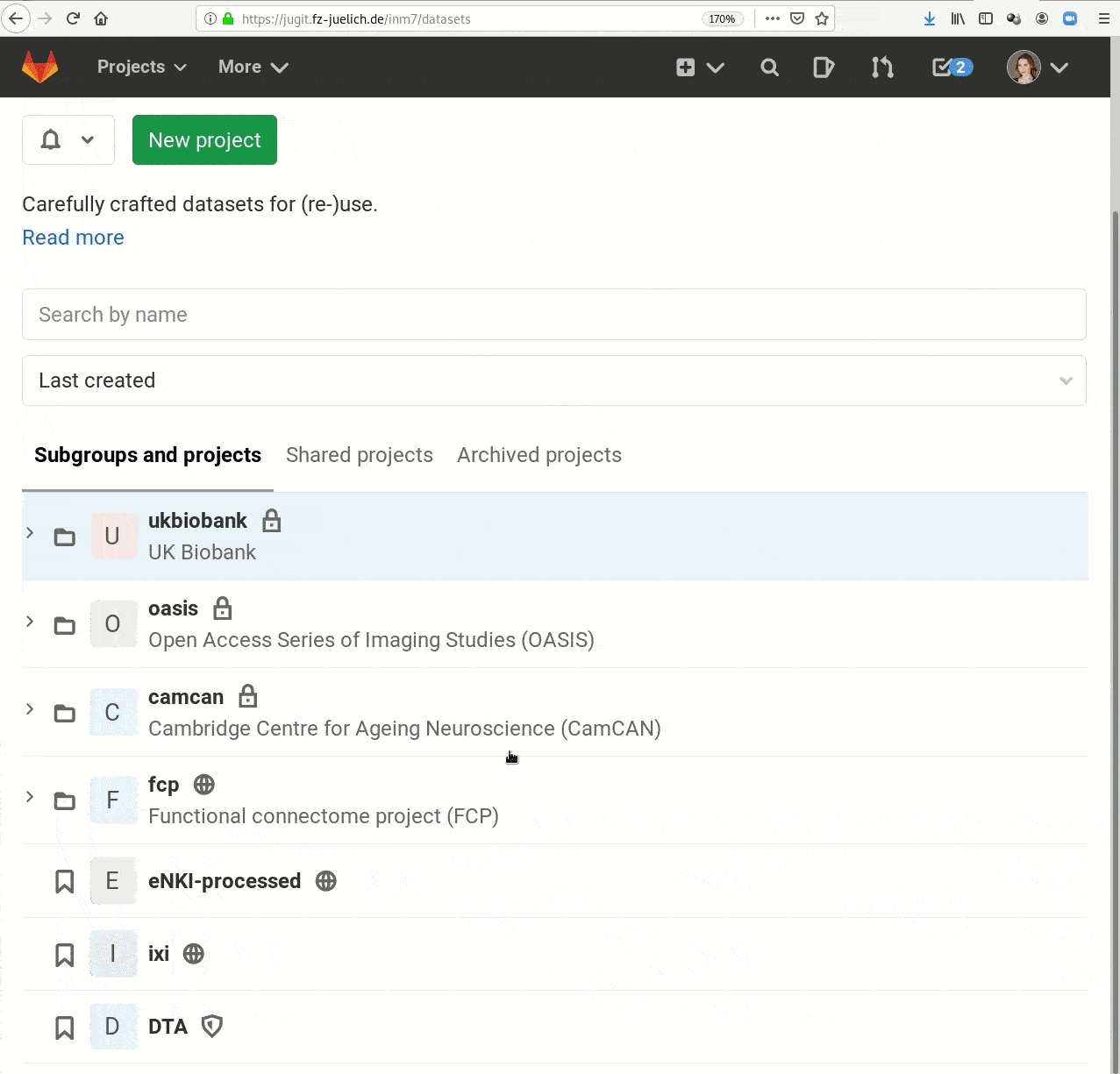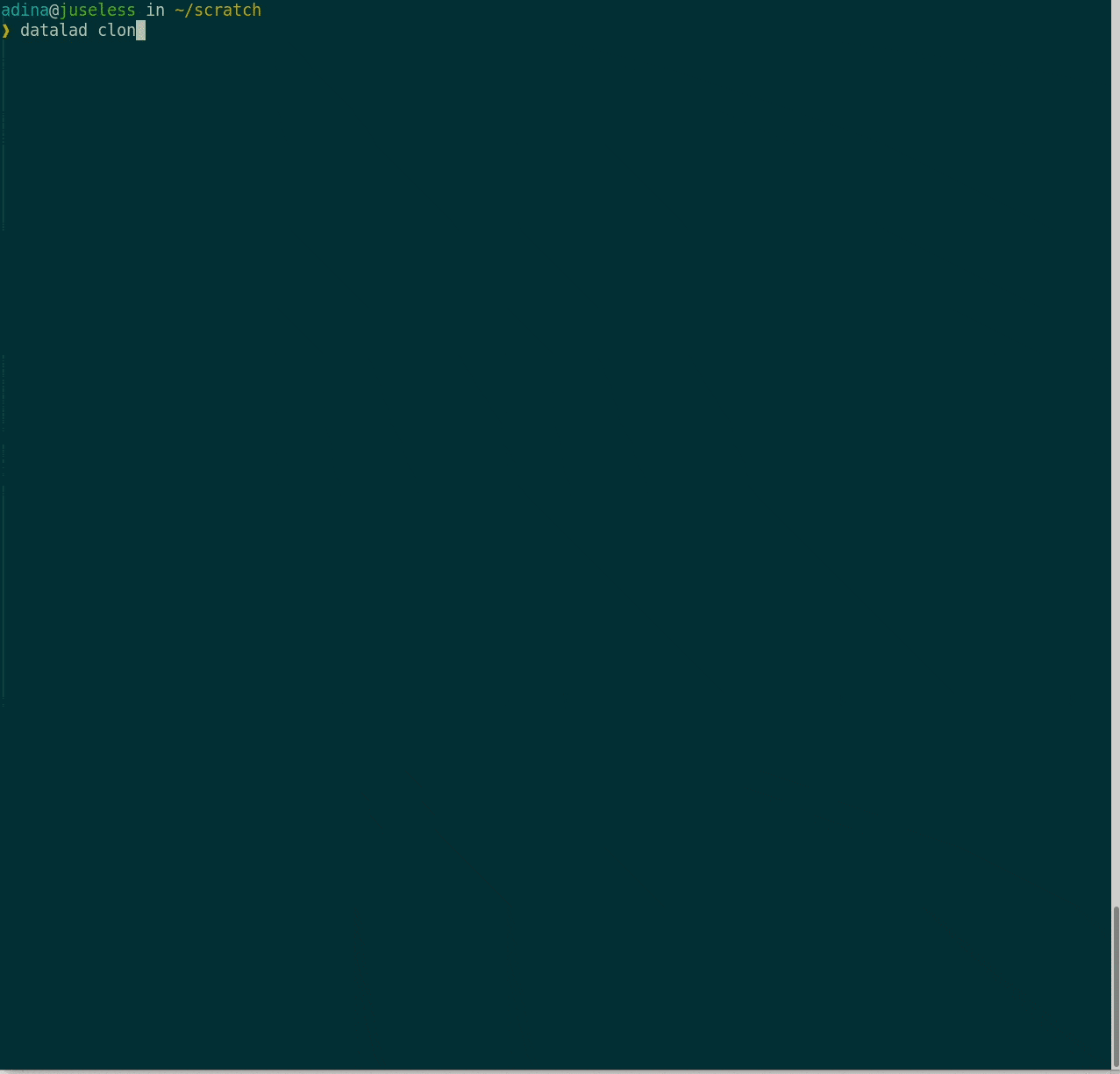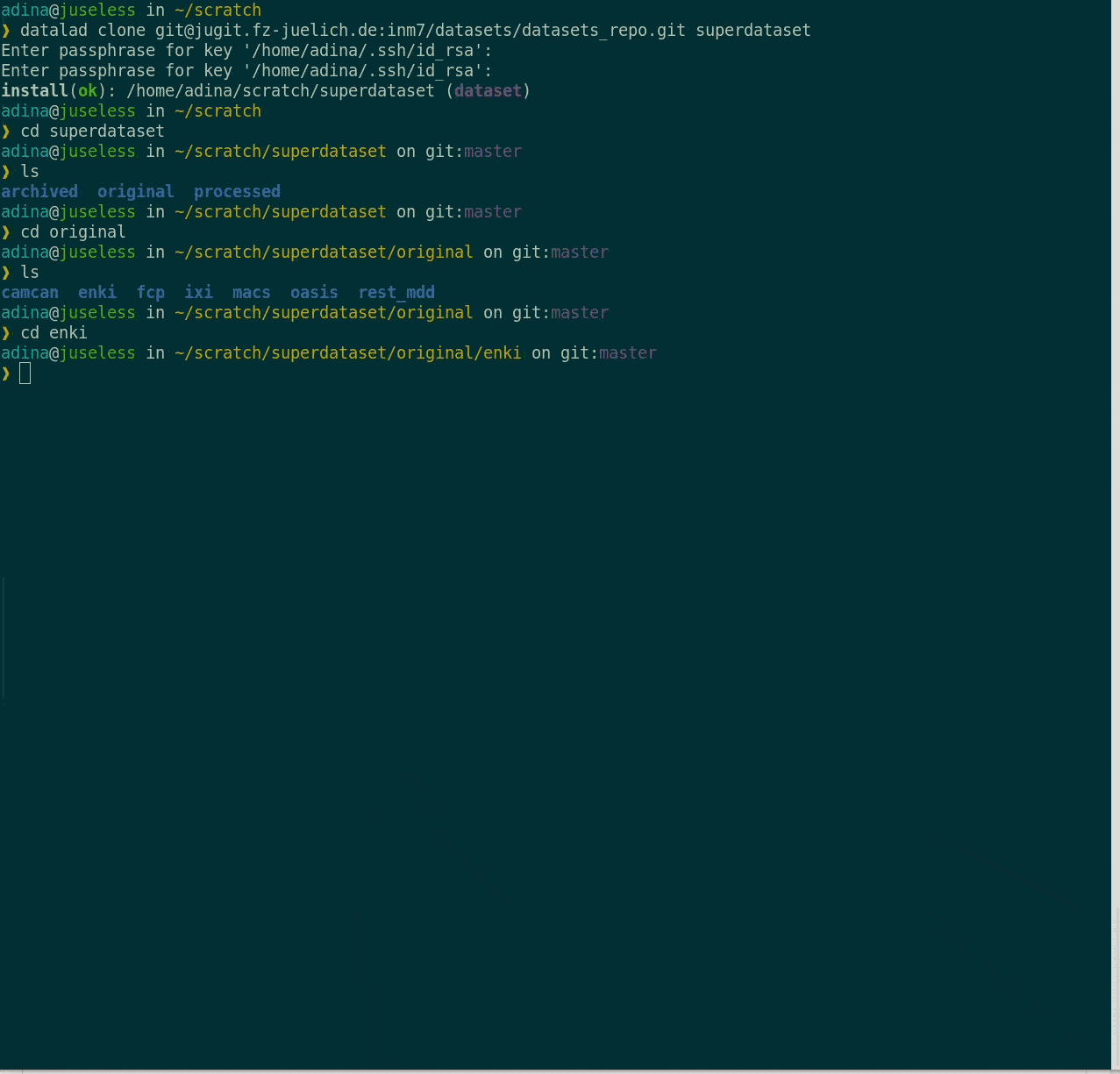
Publishing datasets
- Real-life example 3:
GitHub for repository hosting, data hosting via Amazon S3 (requires DUA)
Publishing datasets
Special case 1: repositories with annex support

Publishing datasets
Special case 2: Special remotes with repositories

Publishing datasets
Special case 1: repositories with annex support
Publishing datasets
Special case 2: Special remotes with repositories
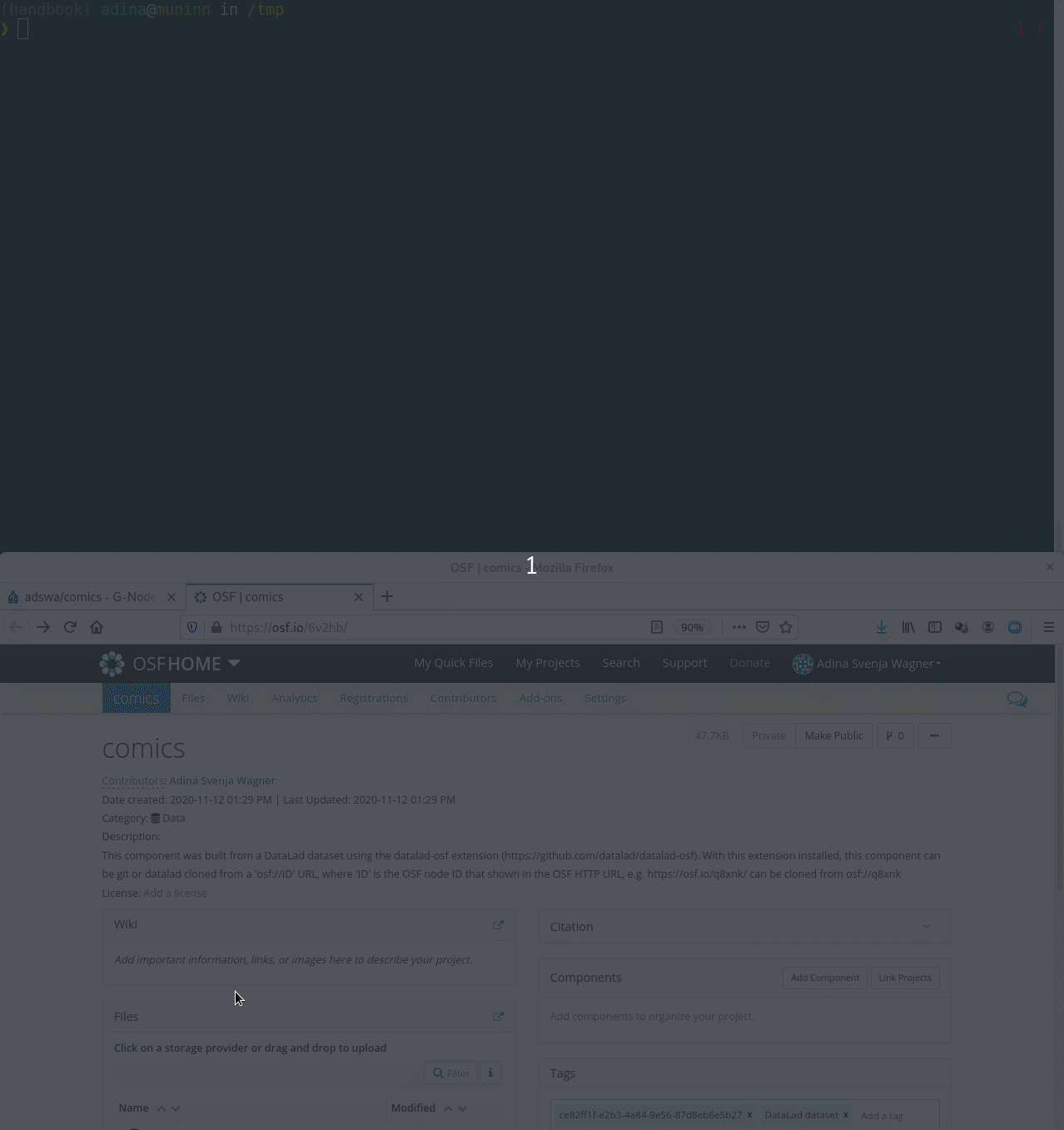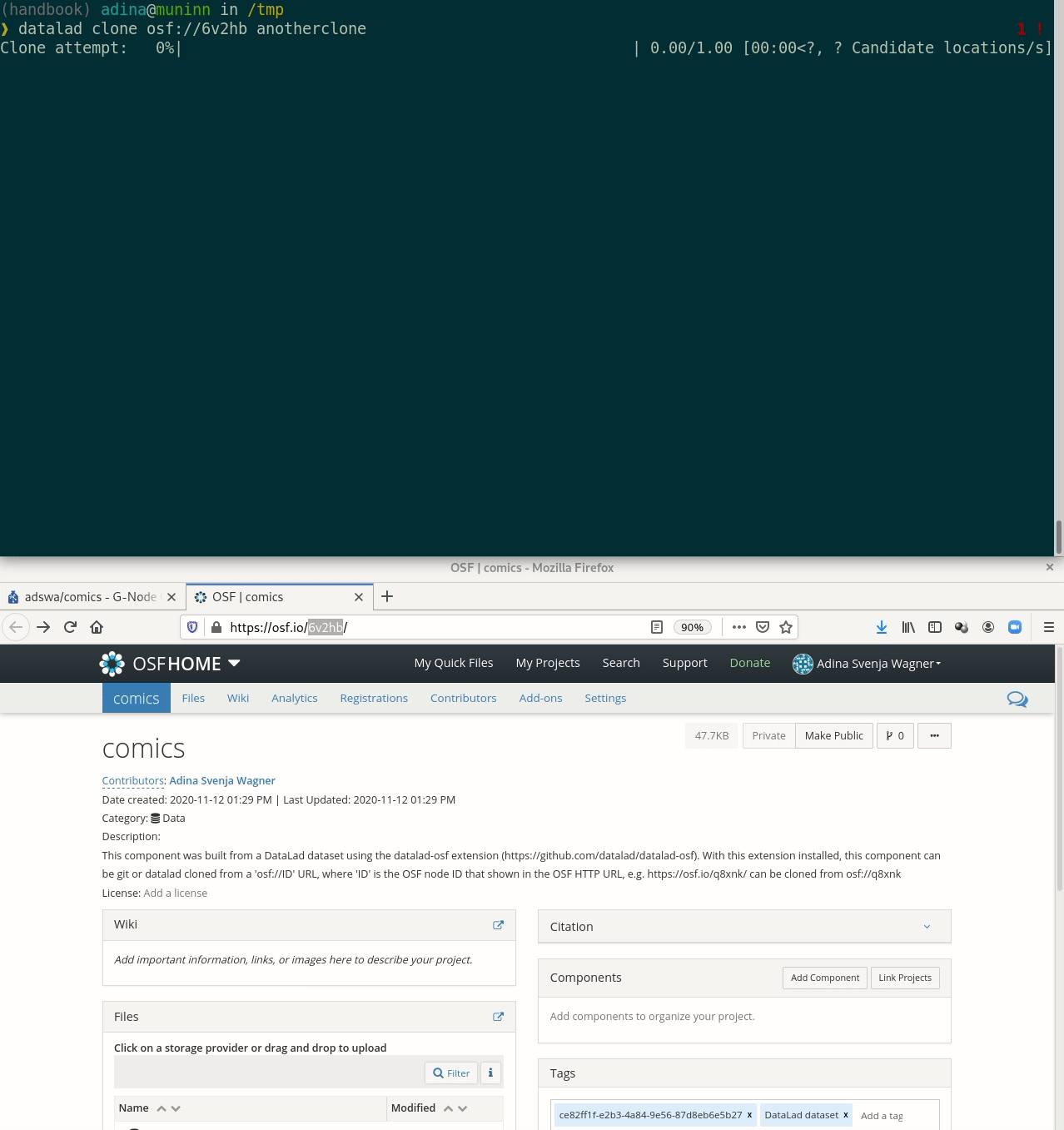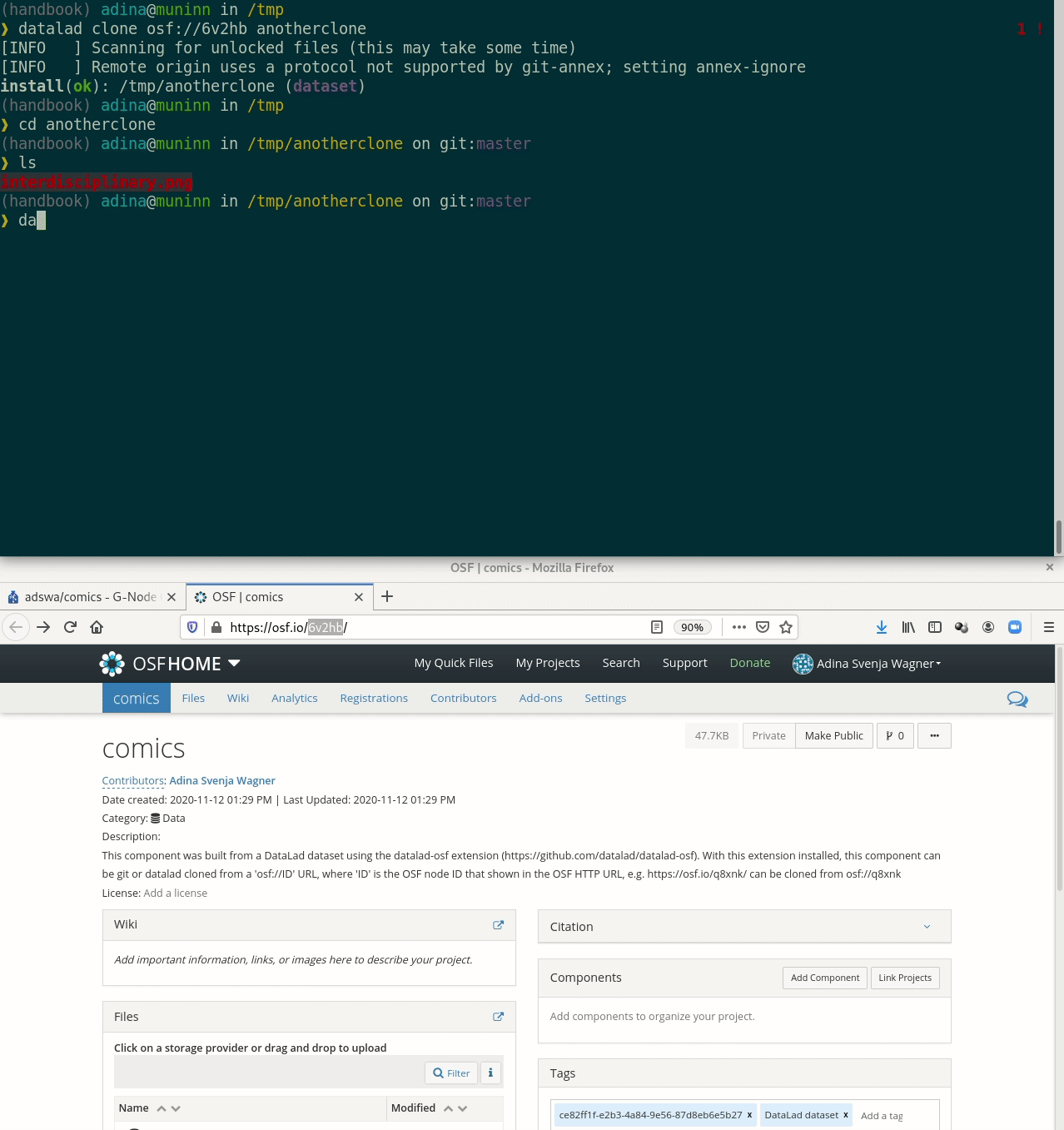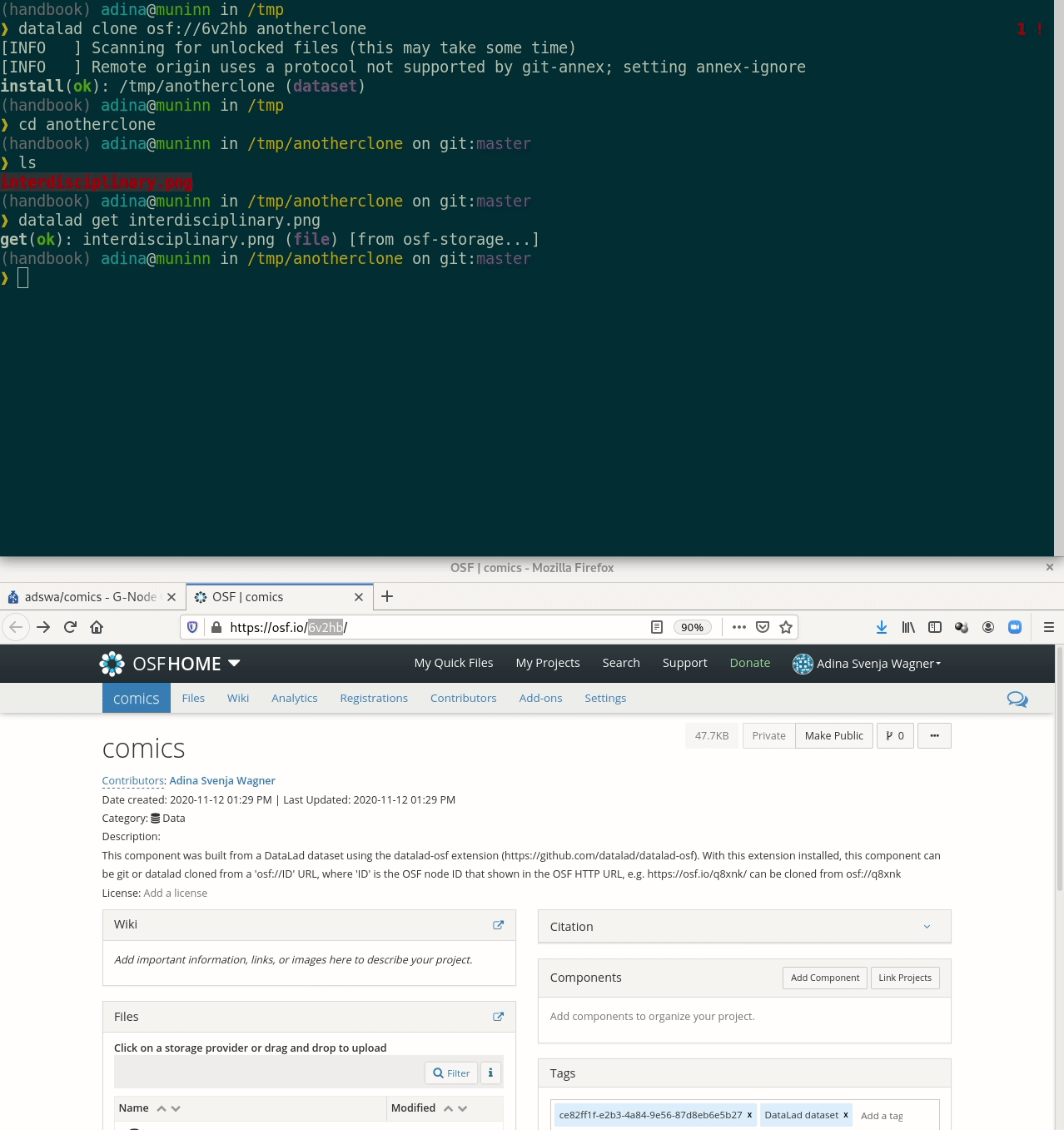
Requires the DataLad extension datalad-osf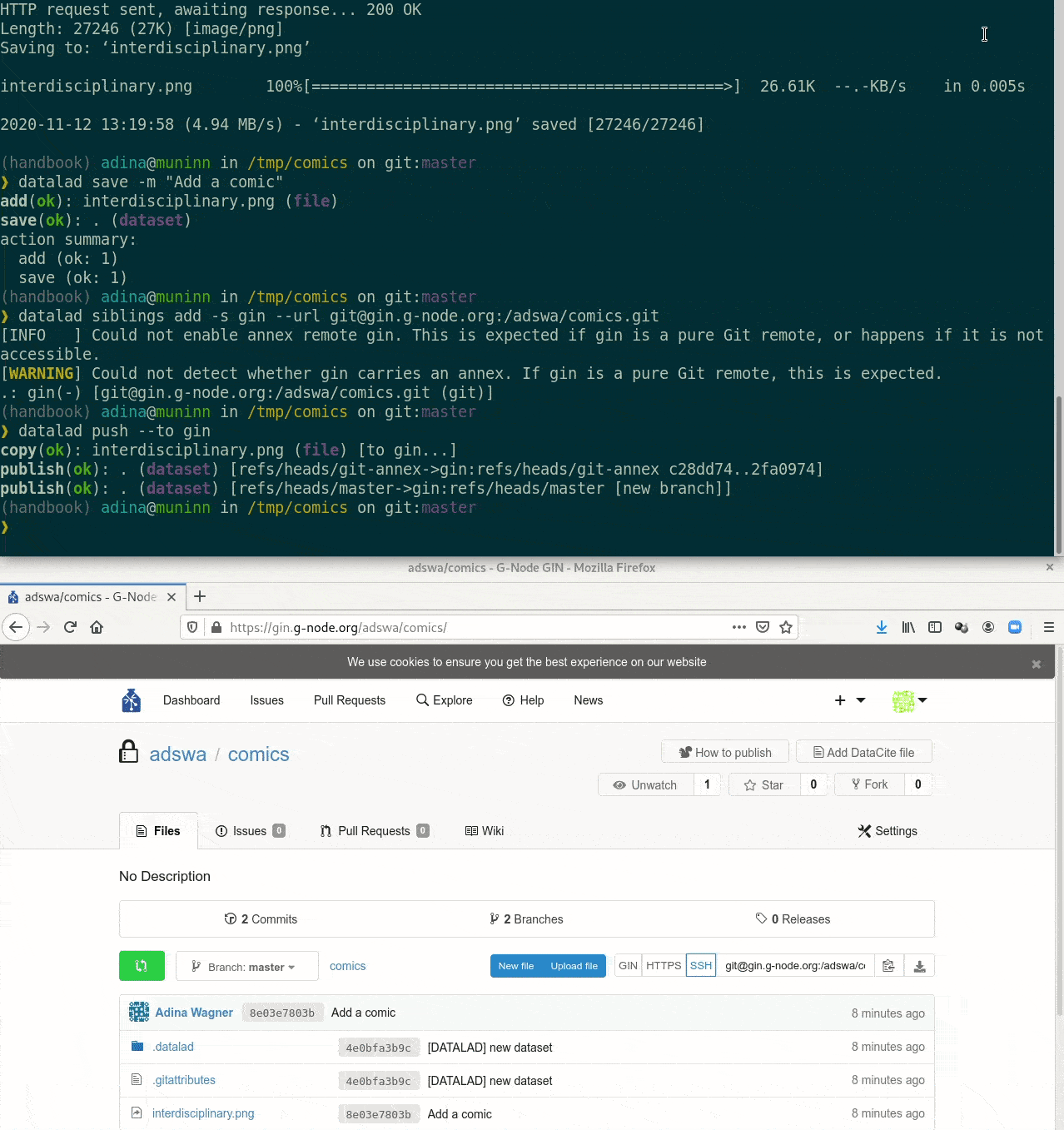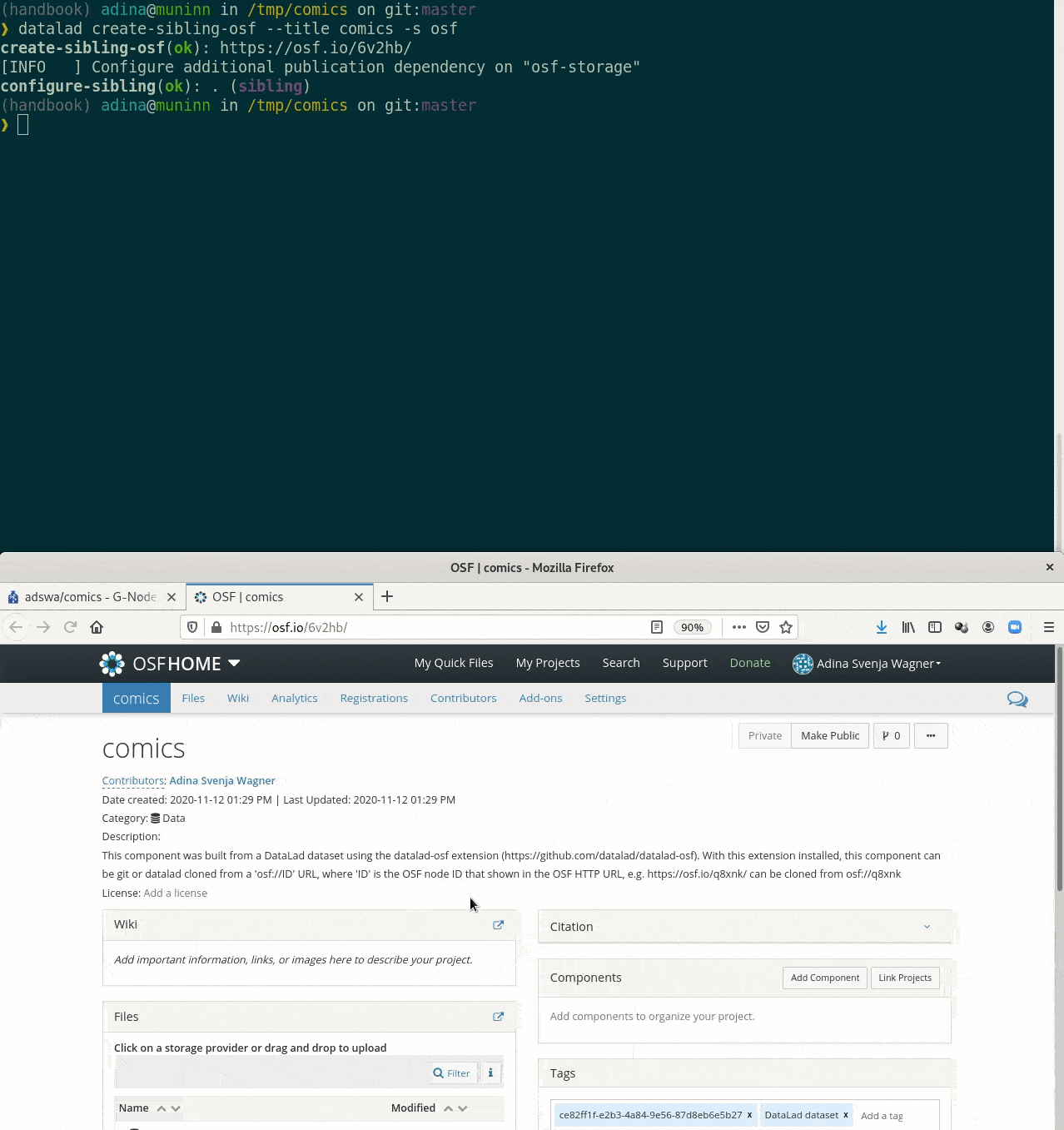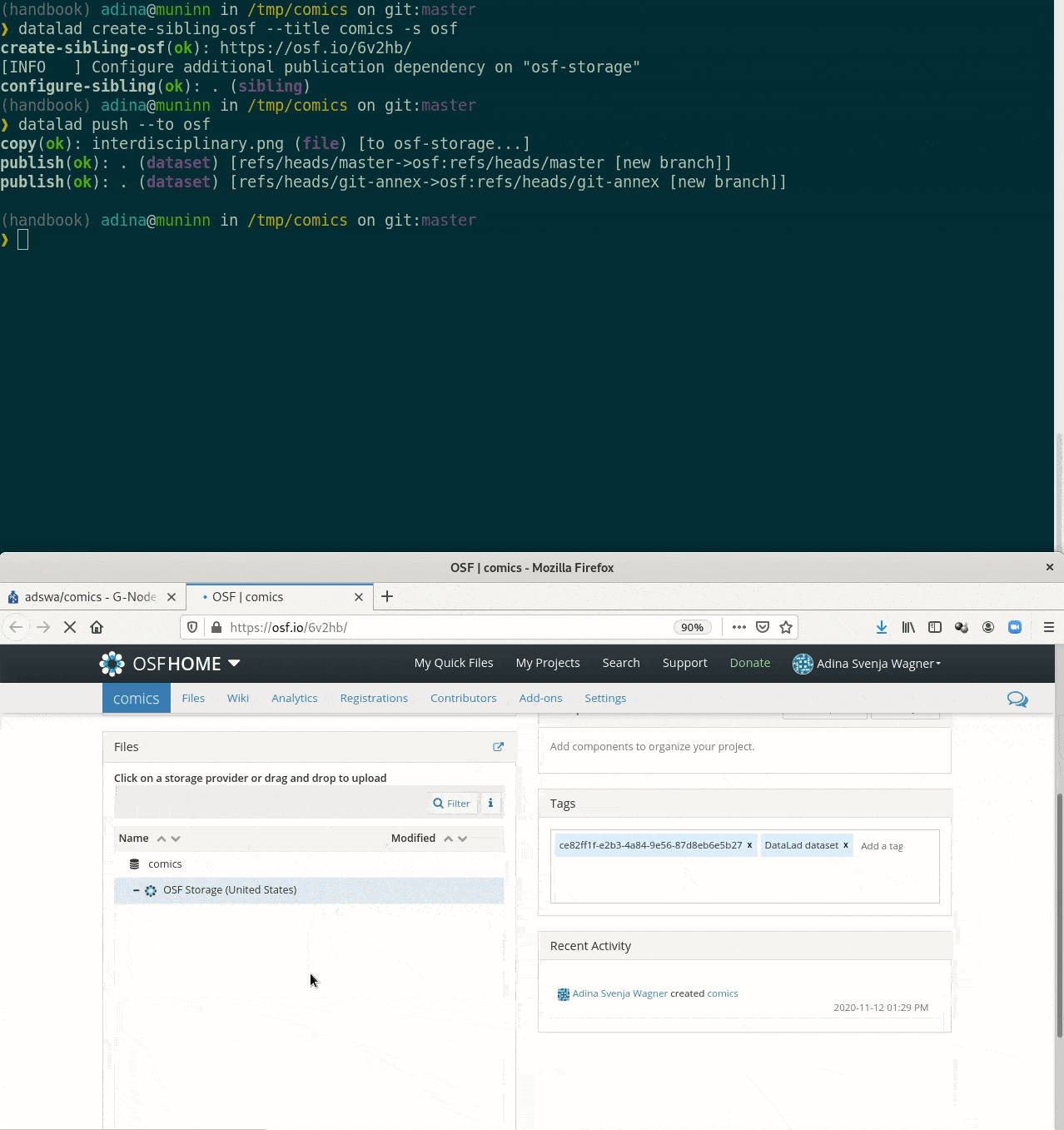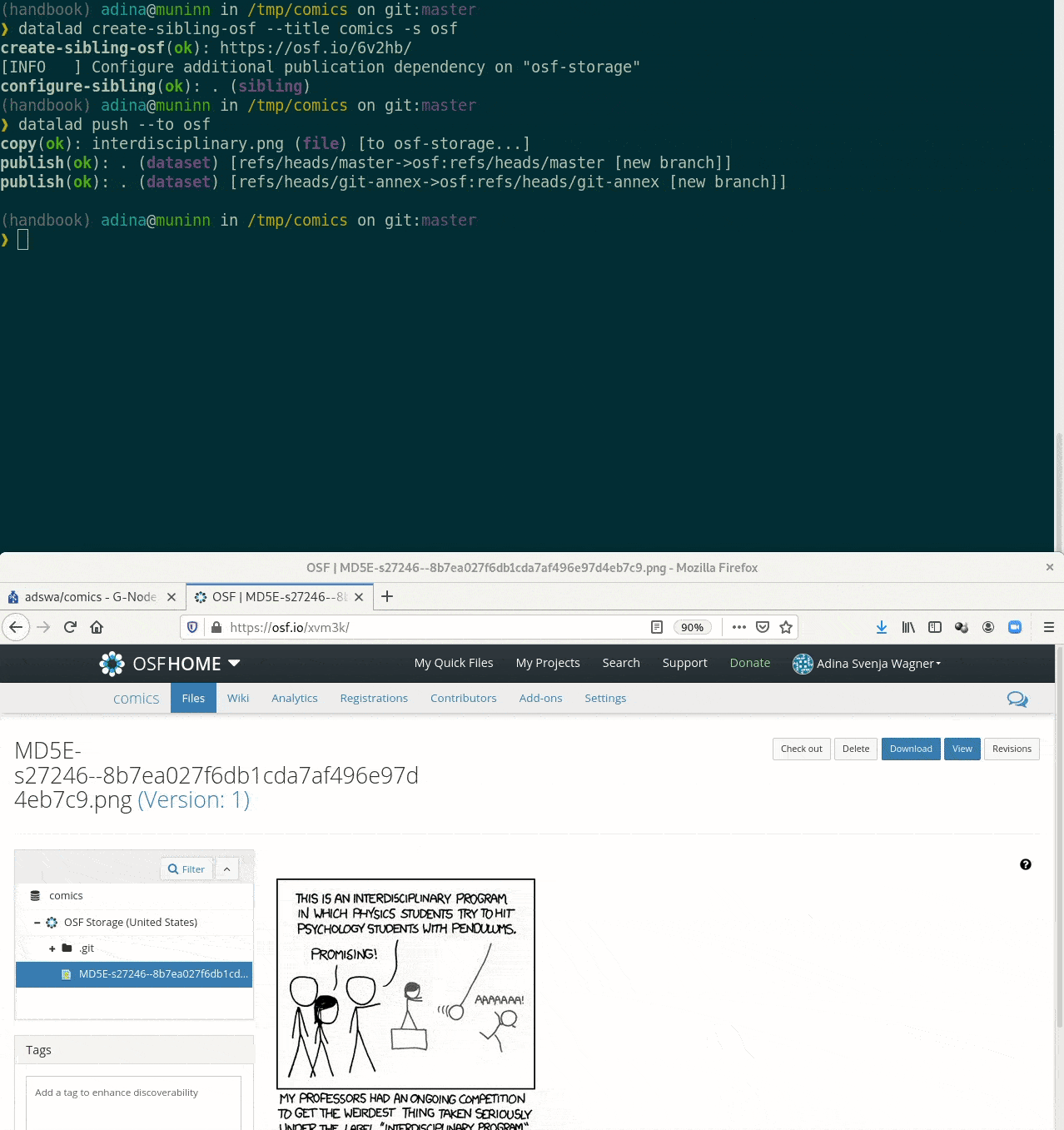
Publishing datasets
Special case 3: RIA stores for dataset hosting/backup
Tutorial for large scale, reproducible computation: github.com/psychoinformatics-de/fairly-big-processing-workflow
Publishing datasets
-
DataLad can create siblings from the command line for the following services:
- GitHub
datalad create-sibling-github- GitLab
datalad create-sibling-gitlab- Gin
datalad create-sibling-gin- Gogs
datalad create-sibling-gogs- local or remote paths
datalad create-sibling- RIA stores
datalad create-sibling-ria- Open Science Framework (needs datalad-osf)
datalad create-sibling-osf
(Additional services being worked on: webdav-based services such as Sciebo, ebrains; if you need something else, get in touch)
Cloning DataLad datasets
How does cloning dataset feel like for a consumer?
Cloning DataLad datasets
How does cloning dataset feel like for a consumer?
Cloning DataLad datasets
How does cloning dataset feel like for a consumer?
Cloning DataLad datasets
Let's take a look at the special cases: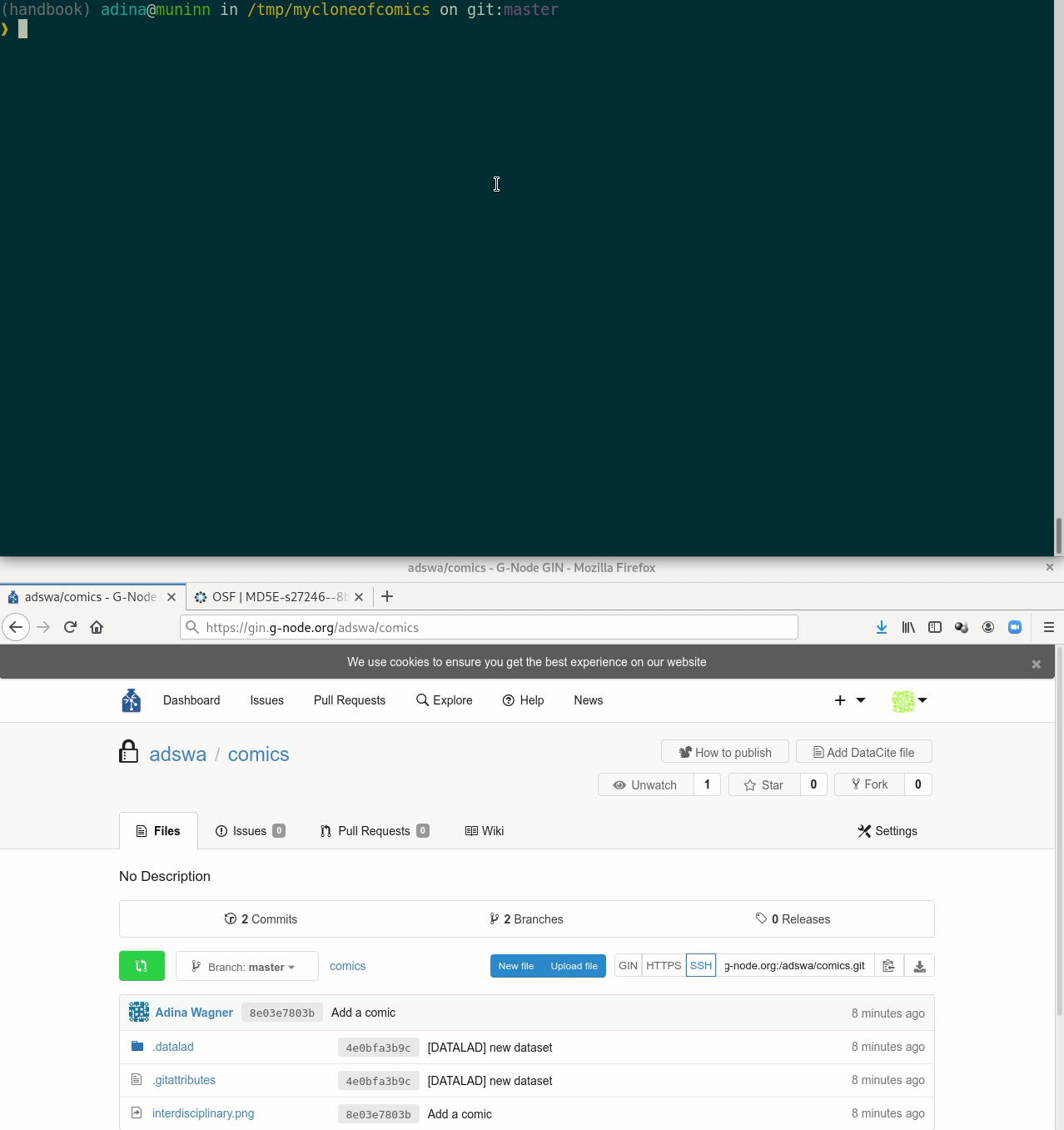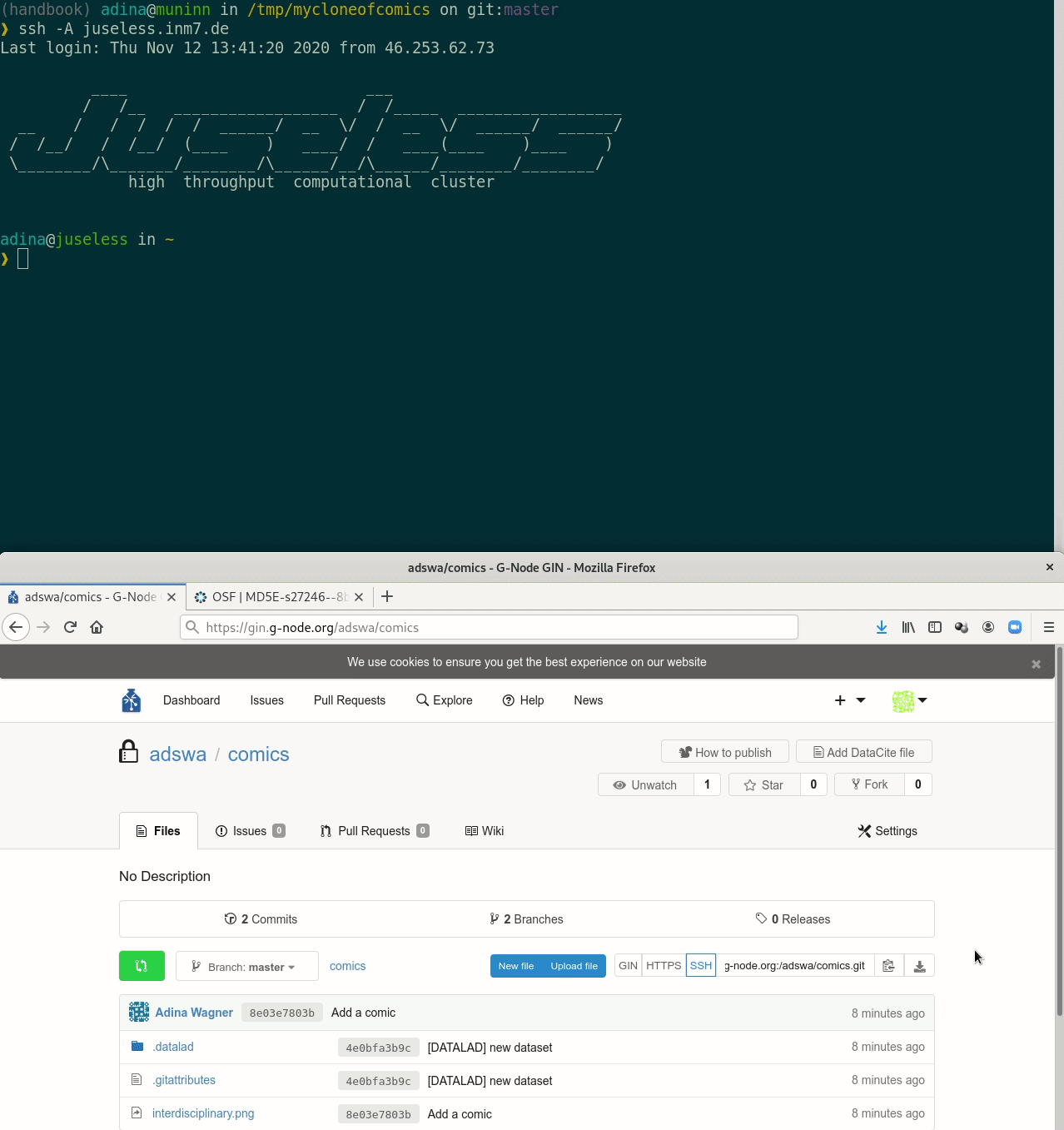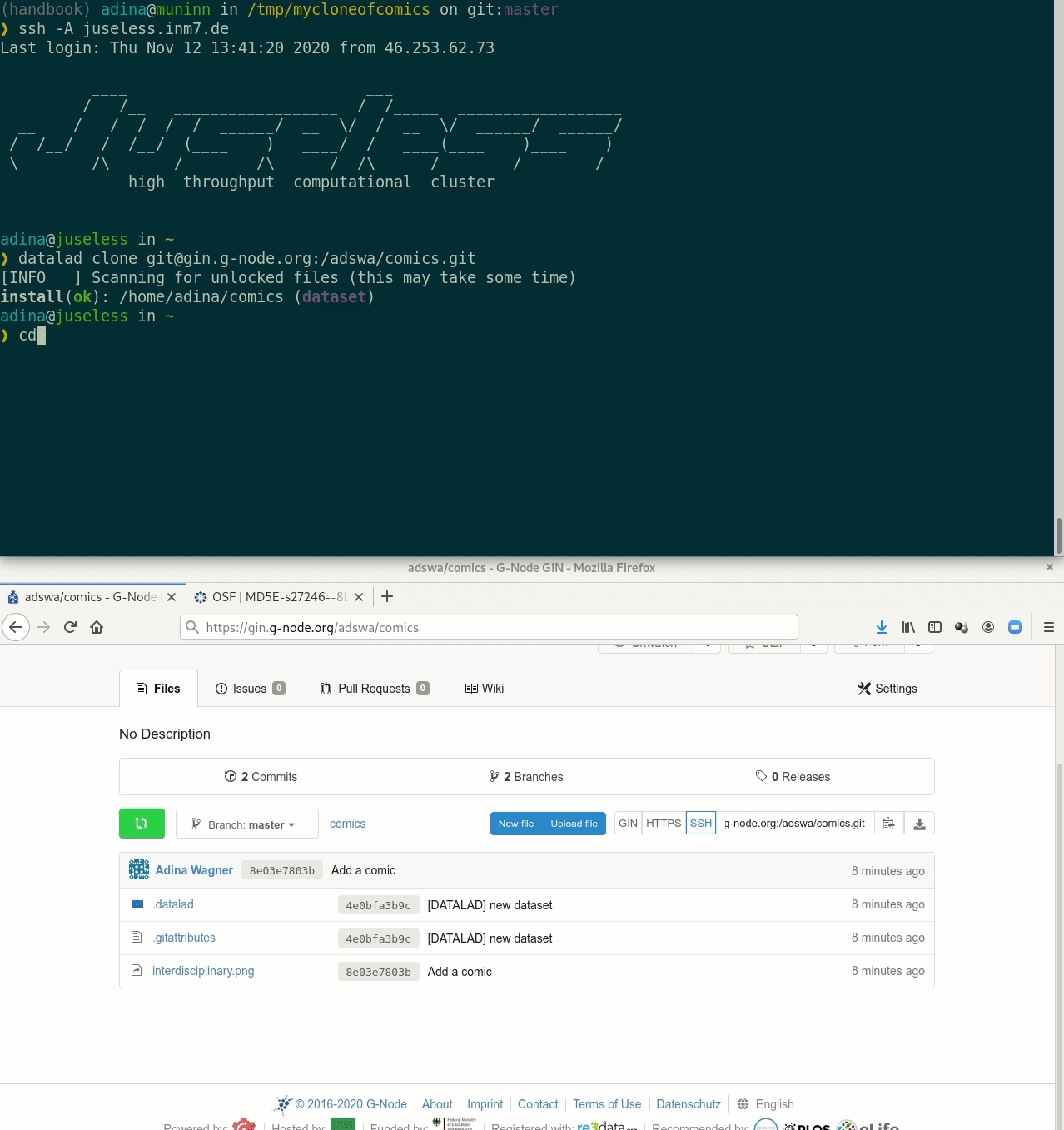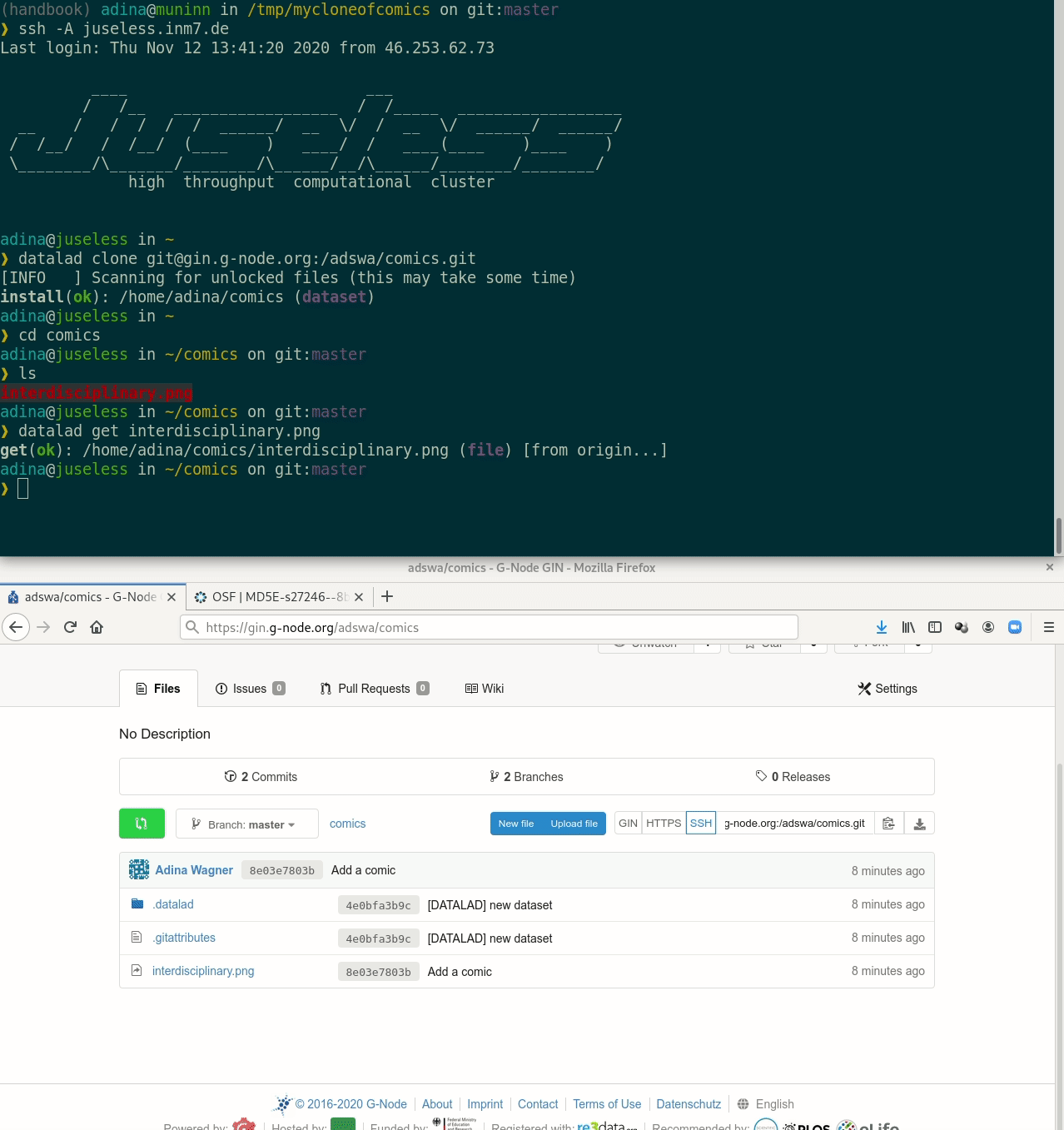
Cloning DataLad datasets
Let's take a look at the special cases:Requires the DataLad extension datalad-osf
Summary: Data publication

- datasets can have "siblings", linked clones in other places
- Those can be local or remote, on commercial, free, or personal infrastructure
- Typical repository hosting services do not host annexed contents
- A notable exception is Gin
- Typical storage providers do not host Git repositories
- but datalad extensions can make it possible for certain services, such as the OSF
- Despite the different possible services, operations are streamlined
- clone installs datasets, get retrieves data, push publishes (new changes in) datasets, update pulls dataset updates. This remains the case even if underlying data hosting changes.
- Siblings serve multiple purposes:
- Personal back-up that's easy to sync; Publicly or privately exposed files to share with (selected) others; Entrypoints for collaborations or others' contributions; ...
Publish your own dataset
Code: psychoinformatics-de.github.io/rdm-course/03-remote-collaboration/index.html#publishing-datasets-to-ginUsing Gin for data publication
-
Gin has a few advantages for publishing data
- DataLad Integration: Convenience commands to create siblings
- Annex support: Easiest possible publication, preview and individual download of annexed contents in the webinterface
- Open Science support: Archive datasets to obtain a DOI; ensures minimal metadata and a license
- Private or Public repositories
- Runs on European infrastructure (some data protection officers like this)
- Free, and with yet unlimited storage
Using Gin for data publication
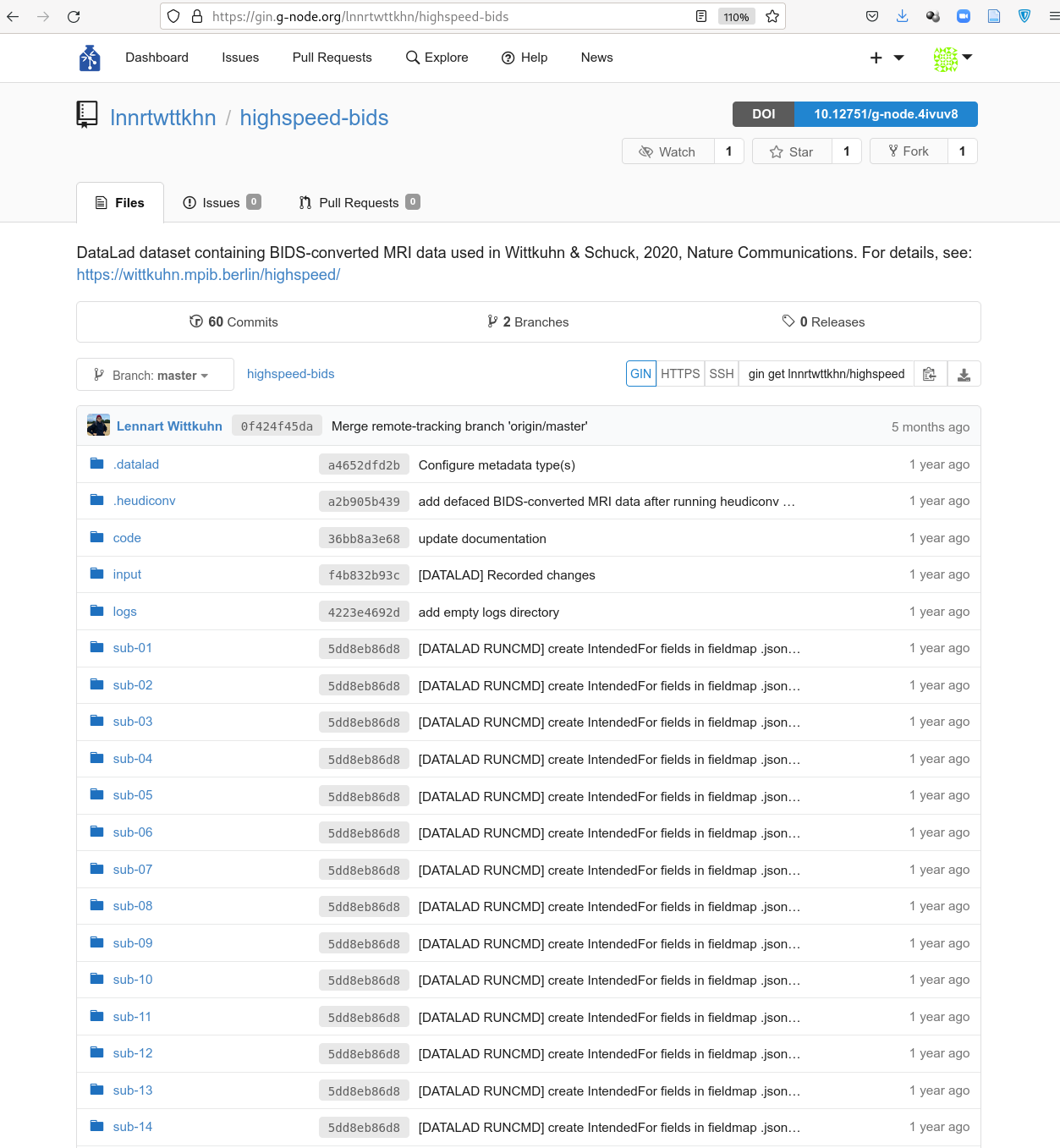
Using Gin for data publication
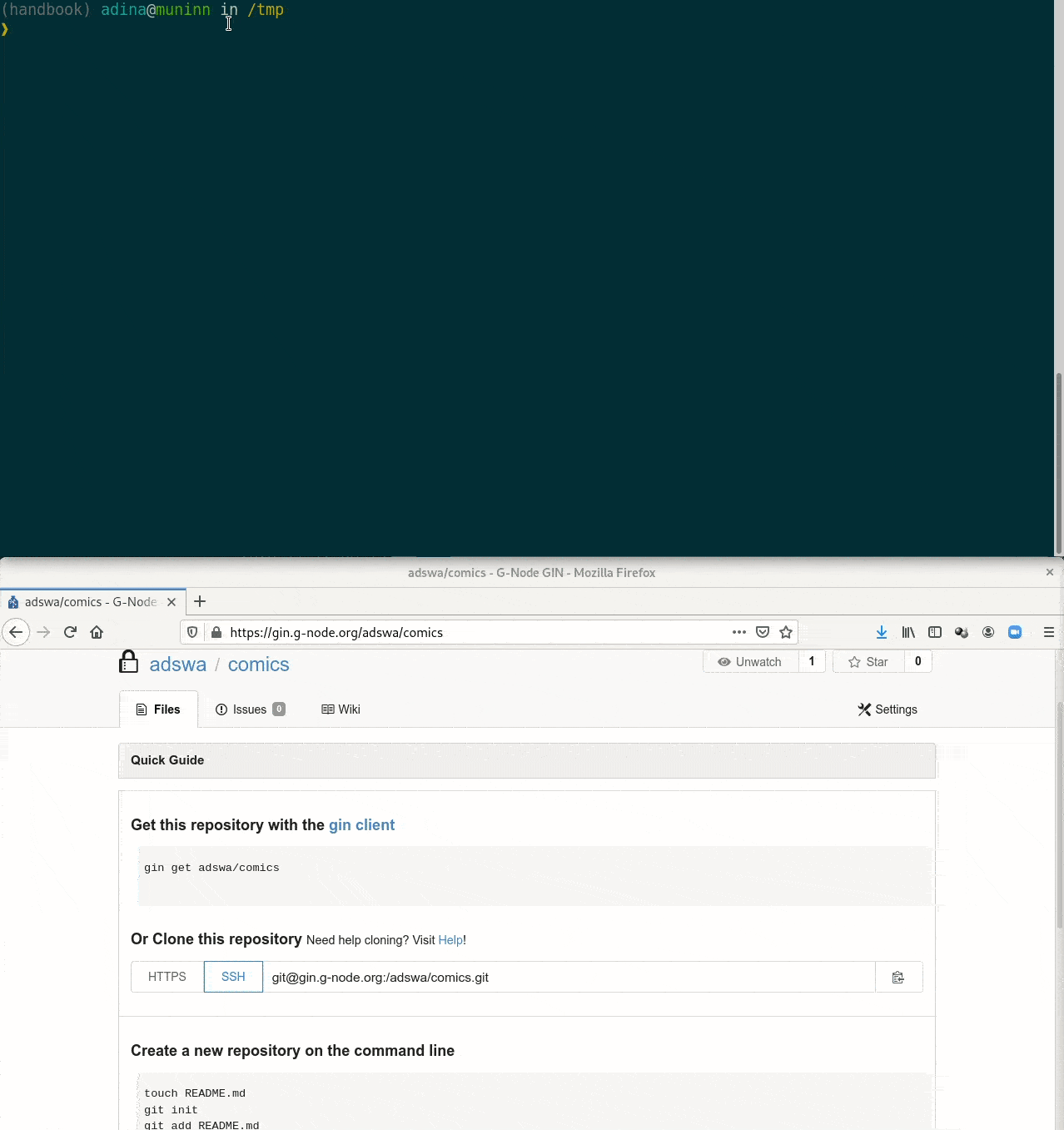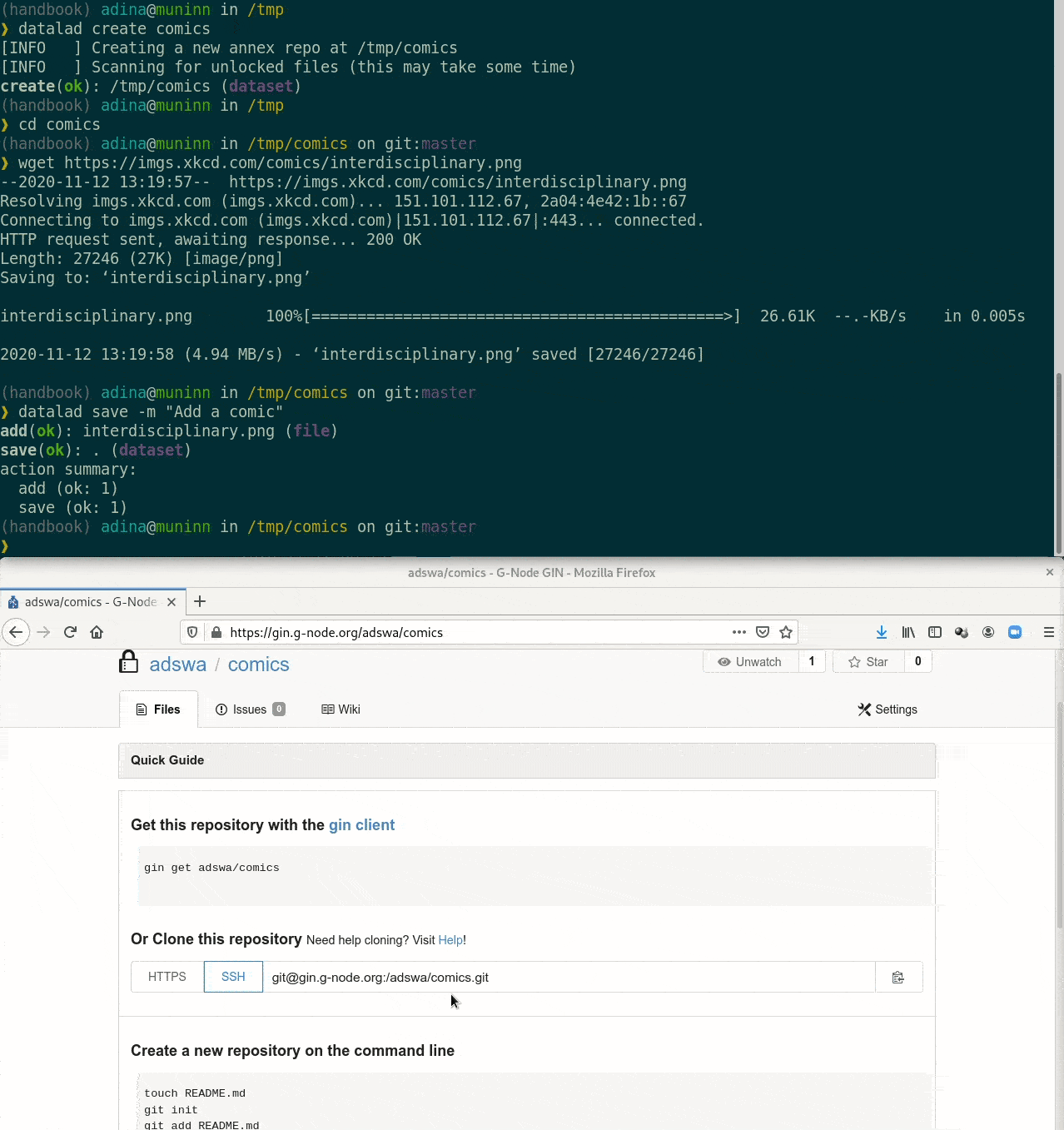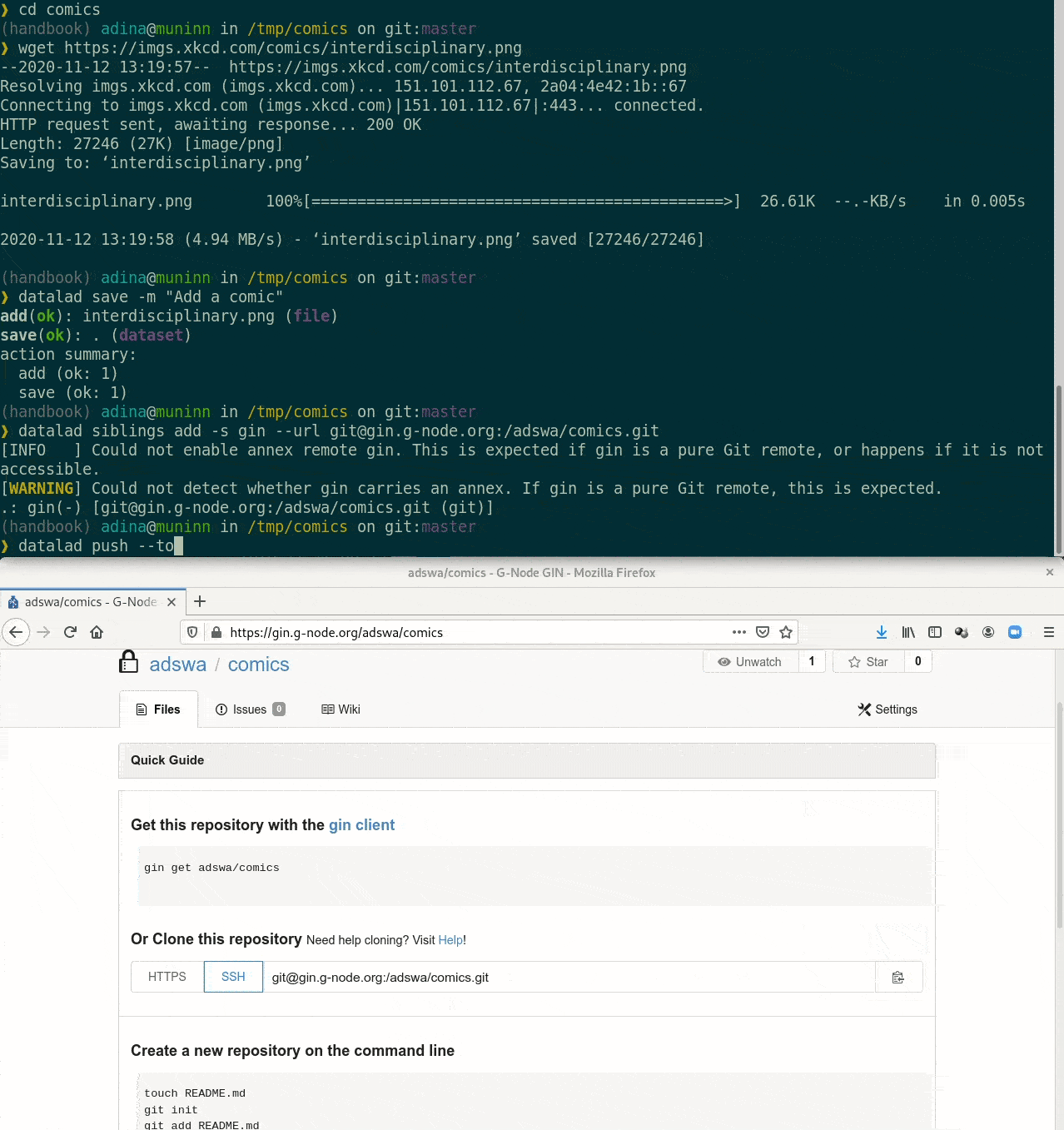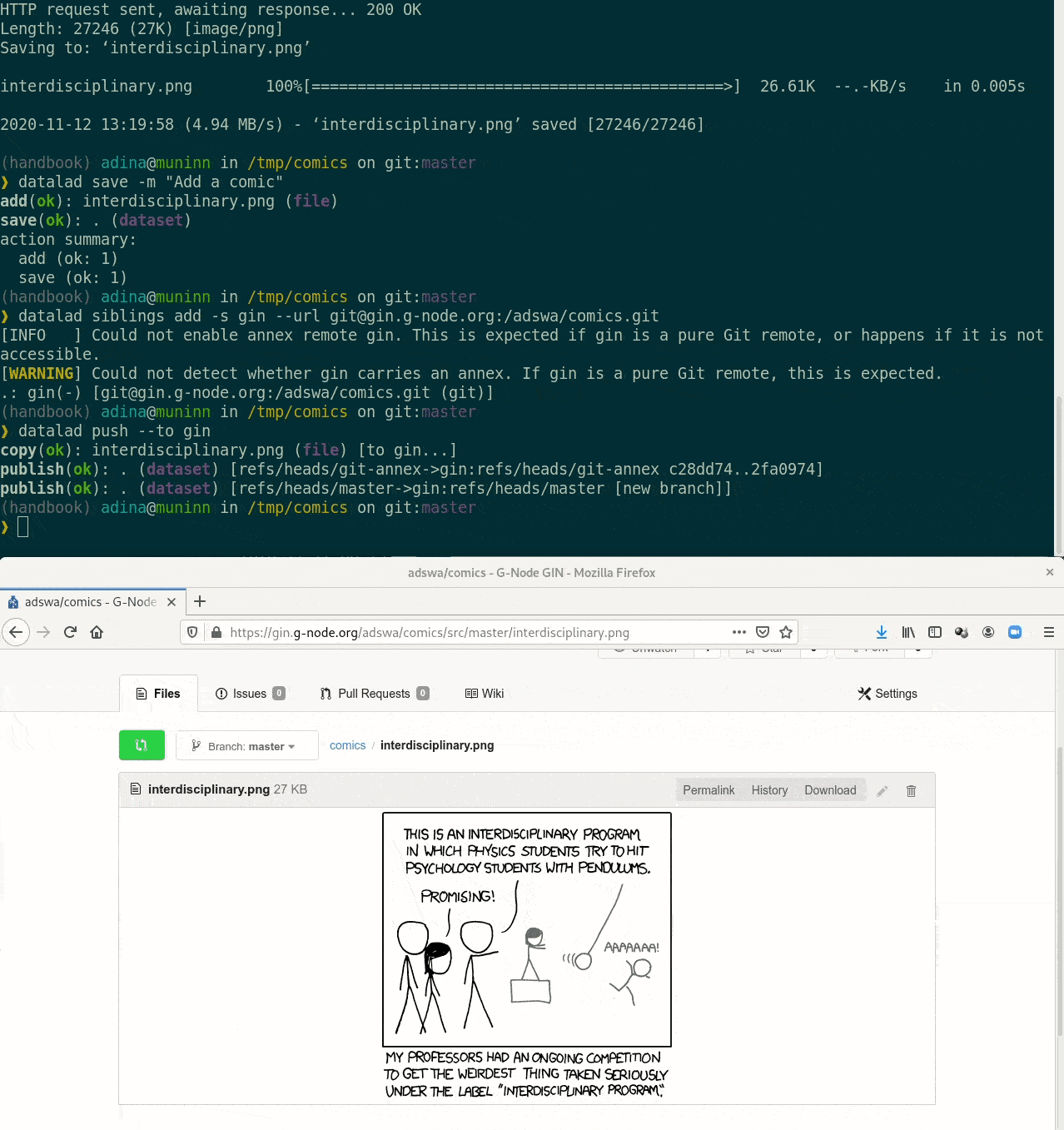
- Step 1: Create a Gin account (requires an email address)
- Step 2: Generate and upload an SSH key
- Step 3: Create and register a sibling repository
- Step 4: Publish your dataset
- Step 5: Update your dataset
Summary: Publishing and updating data (Gin)
- Gin is a free repository hosting service
- To publish datasets to Gin, you need an account and an SSH key
- DataLad has built-in integration with datalad create-sibling-gin
- This requires generating an access token
- Gin has annex support
- datalad push published all dataset contents and the Git history
- The dataset can be cloned from Gin by others
- If the dataset is public, this does not even require a Gin account
- You can still publish your dataset to (your lab's) GitHub/GitLab/other places
- and use Gin only for data hosting. Walkthrough: handbook.datalad.org/basics/101-139-gin.html#ginbts
Next: Let's collaborate!