Data management with DataLad
an Introduction
Adina Wagner
 @AdinaKrik
@AdinaKrik |
|
|
Psychoinformatics lab,
Institute of Neuroscience and Medicine, Brain & Behavior (INM-7) Research Center Jülich |
Slides: https://github.com/datalad-handbook/course/
What is (research) data management?
- (Research) Data = every digital object involved in your project: code, software/tools, raw data, processed data, results, manuscripts ...
- ... needs to be properly managed - from creation to use, publication, sharing, archiving, re-use, destruction... (keyword: FAIR data)

- Research data management is a key component for reproducibility, efficiency, and impact/reach of data analysis projects
Why data management?

- Funders & publishers require it
- Scientific peers increasingly expect it
- The quality and efficiency of your work improves
The most interesting datasets of our field require it!

- Exciting datasets (UKBiobank, HCP, ...) are orders of magnitudes larger than previous public datasets, and neither the computational infrastructure nor analysis workflows scale to these dataset sizes.
How is (research) data management possible?
There are tools and concepts that can help:
- Version control your data
- Document everything, ideally automatically (Provenance capture)
Why version control?

- keep things organized
- keep track of changes
- Mostly done for code, but data changes as well!
Why provenance capture?

- Data Provenance: How did a digital object come to be in its present form?
- Many uses, but among others, it aids the reproducibility of science
- Who generated an output and when?
- Which (version of which) data was used, and where does this input data come from?
- Which scripts with which parameters created which results, and how?
- What is the software (libraries, environment) used for a computation and its dependencies to data or code?
DataLad can help with data management
- What is it?
- Why should I use it?
- How can I use it?
Reproducible paper - a Magic trick?
If curious, you can read up all the details and a step-by-step instruction here.  in brief
in brief
- A command-line tool, available for all major operating systems (Linux, macOS/OSX, Windows)
- Build on top of Git and Git-annex
- Allows...
- ... version-controlling arbitrarily large content,
- ... easily sharing and obtaining data (note: no data hosting!),
- ... (computationally) reproducible data analysis,
- ... and much more
- Completely domain-agnostic
- Today: Basic concepts and commands.
| ⮊ For more: Read the DataLad Handbook |
DataLad Datasets
- DataLad's core data structure
- Dataset = A directory managed by DataLad
- Any directory of your computer can be managed by DataLad.
- Datasets can be created (from scratch) or installed
- Datasets can be nested: linked subdirectories
Experience a DataLad dataset
Code to follow along: http://handbook.datalad.org/en/latest/code_from_chapters/01_dataset_basics_code.htmlLocal version control
Procedurally, version control is easy with DataLad!

Advice:
- Save meaningful units of change
- Attach helpful commit messages
Summary - Local version control
datalad createcreates an empty dataset.- Configurations (-c yoda, -c text2git) are useful.
- A dataset has a history to track files and their modifications.
- Explore it with Git (git log) or external tools (e.g., tig).
datalad saverecords the dataset or file state to the history.- Concise commit messages should summarize the change for future you and others.
datalad download-urlobtains web content and records its origin.- It even takes care of saving the change.
datalad statusreports the current state of the dataset.- A clean dataset status is good practice.
Consuming datasets

- Datasets are light-weight: Upon installation, only small files and meta data about file availability are retrieved.
- Content can be obtained on demand via
datalad get.
Dataset nesting

Summary - Dataset consumption & nesting
datalad cloneinstalls a dataset.- It can be installed “on its own”: Specify the source (url, path, ...) of the dataset, and an optional path for it to be installed to.
- Datasets can be installed as subdatasets within an existing dataset.
- The --dataset/-d option needs a path to the root of the superdataset.
- Only small files and metadata about file availability are present locally after an install.
- To retrieve actual file content of larger files,
datalad getdownloads large file content on demand. datalad statuscan report on total and retrieved repository size- using
--annexand--annex alloptions. - Datasets preserve their history.
- The superdataset records only the version state of the subdataset.
reproducible data analysis

Code to follow along: http://handbook.datalad.org/en/latest/code_from_chapters/10_yoda_code.html
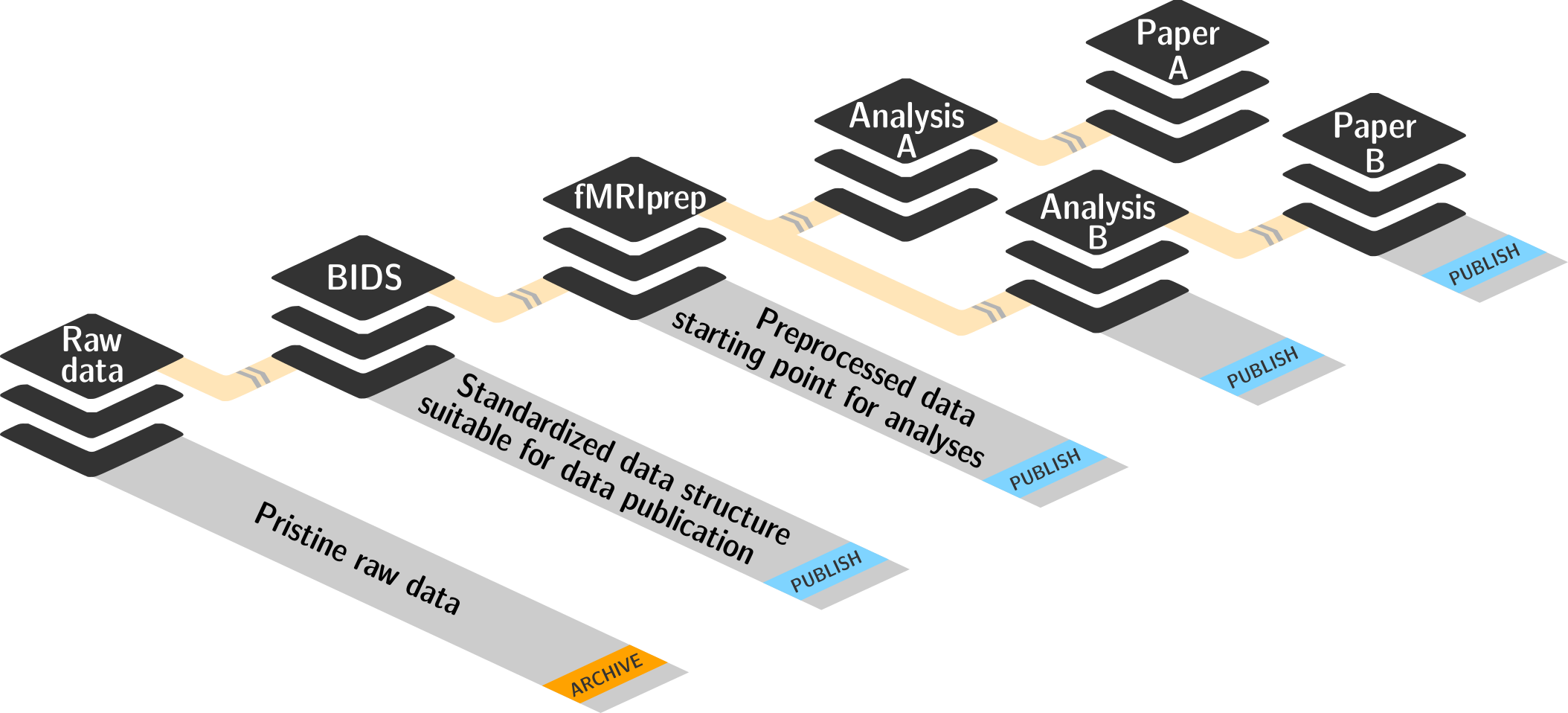
Basic organizational principles for datasets
- Keep everything clean and modular
 |
|
- do not touch/modify raw data: save any results/computations outside of input datasets
- Keep a superdataset self-contained: Scripts reference subdatasets or files with relative paths
Basic organizational principles for datasets
- Record where you got it from, where it is now, and what you do to it

- Document everything:
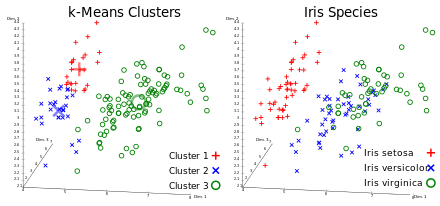
A classification analysis on the iris flower dataset

Reproducible execution & provenance capture
datalad run

Computational reproducibility
- Code may produce different results or fail if run in a different software environment
- DataLad datasets can store (and share) software environments (Docker or Singularity containers) and reproducibly execute code inside of the software container, capturing software as additional provenance
- DataLad extension:
datalad-container
datalad-containers run

How to get started with DataLad
- Read the DataLad handbook
- An interactive, hands-on crash-course (free and open source)
- Check out or used public DataLad datasets, e.g., from OpenNeuro
-
$ datalad clone ///openneuro/ds000001 [INFO ] Cloning http://datasets.datalad.org/openneuro/ds000001 [1 other candidates] into '/tmp/ds000001' [INFO ] access to 1 dataset sibling s3-PRIVATE not auto-enabled, enable with: | datalad siblings -d "/tmp/ds000001" enable -s s3-PRIVATE install(ok): /tmp/ds000001 (dataset) $ cd ds000001 $ ls sub-01/* sub-01/anat: sub-01_inplaneT2.nii.gz sub-01_T1w.nii.gz sub-01/func: sub-01_task-balloonanalogrisktask_run-01_bold.nii.gz sub-01_task-balloonanalogrisktask_run-01_events.tsv sub-01_task-balloonanalogrisktask_run-02_bold.nii.gz sub-01_task-balloonanalogrisktask_run-02_events.tsv sub-01_task-balloonanalogrisktask_run-03_bold.nii.gz sub-01_task-balloonanalogrisktask_run-03_events.tsv
Acknowledgements
|
|