Data management
Session 01
DataLad Datasets
DataLad datasets are DataLad's core data structure. Datasets have many features:
- Version controlled content, regardless of size
- Relying on the tools Git and Git-annex working in the background.
- Provenance tracking
- Record and find out how data came into existence (including the software environment), and reproduce entire analyses.
- Easy collaboration
- Install others' datasets, share datasets, publish datasets with third-party services.
- Staying up to date
- Datasets can know their copies or origins. This allows to update datasets from their sources with a single command.
- Modularity & Nesting
- Individual datasets are independent, versioned components that can be nested as subdatasets in superdatasets. Subdatasets have a stand-alone version history, and their version state is recorded in the superdataset.
DataLad Datasets
DataLad datasets look like any other directory on your computer, and subdatasets
look like subdirectories. DataLad, Git-annex, and Git work in the background
(e.g., .datalad/, .git/, ...).
You can create & populate a dataset from scratch, or install existing datasets from collaborators or open sources.
DataLad Datasets for data analysis
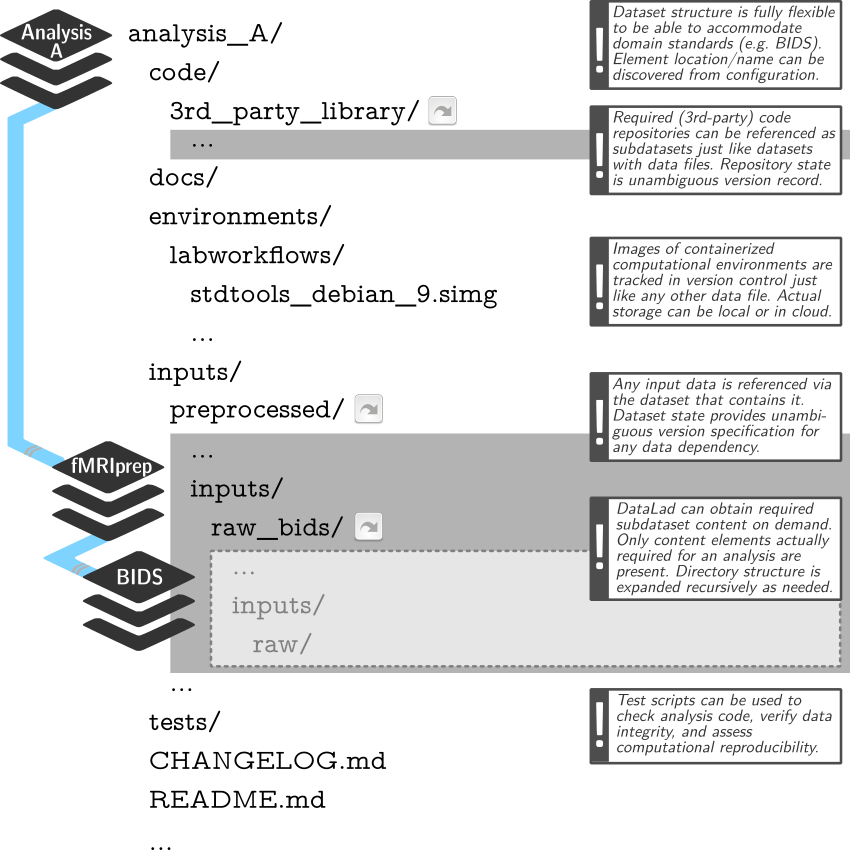
- A DataLad dataset can have any structure, and use as many or few features of a dataset as required.
- However, for data analyses it is beneficial to make use of DataLad features and structure datasets according to the YODA principles:

- P1: One thing, one dataset
- P2: Record where you got it from, and where it is now
- P3: Record what you did to it, and with what
Hands-on solution
- transform the zip folder into a DataLad dataset:
$ cd example_dicom_functional_block
$ datalad create -f
[INFO ] Creating a new annex repo at [...]/example-dicom-functional-1block
create(ok): [...]example-dicom-functional-1block (dataset)
$ datalad save -m "add dicoms from functional acquisition" .
add(ok): LICENSE (file)
add(ok): dicoms/MR.1.3.46.670589.11.38317.5.0.4476.2014042516045740754 (file) [...]
- create a dataset for a data analysis (independent from the data directory)
$ cd ../
$ datalad create -c yoda myanalysis
[INFO ] Creating a new annex repo at [...]/myanalysis
[INFO ] Running procedure cfg_yoda
[INFO ] == Command start (output follows) =====
[INFO ] == Command exit (modification check follows) =====
create(ok): [...]/myanalysis (dataset)
- create a data directory and install the dicom dataset as a subdataset
$ cd myanalysis
$ mkdir data
$ datalad install -d . -s ../example_dicom_functional_1block data/dicoms
[INFO ] Cloning ../example-dicom-functional-1block into '[...]/myanalysis/data/dicoms'
install(ok): data/dicoms (dataset)
action summary:
add (ok: 2)
install (ok: 1)
save (ok: 1)