An introduction to DataLad
👩💻👨💻
with a focus on ML application
Adina Wagner
 @AdinaKrik
@AdinaKrik |
|
|
Psychoinformatics lab,
Institute of Neuroscience and Medicine, Brain & Behavior (INM-7) Research Center Jülich |
Slides: https://github.com/datalad-handbook/course/
Acknowledgements
|
Funders




Collaborators
|
Resources and Further Reading
|
Comprehensive user documentation in the DataLad Handbook (handbook.datalad.org) |
|
 |
|
 |
|
 |
|
Resources and Further Reading
- Specifically relevant handbook sections to ML:
- DataLad ML example:
handbook.datalad.org/r.html?ml-usecase - Code list with further links: handbook.datalad.org/r.html?FZJmlcode
- Not-text-based resources:
- DataLad Youtube channel with talks and tutorials
Questions/interaction
Live polling system
Live coding
- Live-demonstration of DataLad examples and workflows throughout the talk
- Code along with copy-paste code snippets: handbook.datalad.org/r.html?FZJmlcode
- Requirements:
- DataLad version >= 0.12 (installation instructions at handbook.datalad.org)
- For containerized analyses: DataLad extension datalad-containers (available via pip) + Singularity
- A command-line tool, available for all major operating systems (Linux, macOS/OSX, Windows), MIT-licensed
- Build on top of Git and Git-annex
- Allows...
- ... version-controlling arbitrarily large content
- version control data and software alongside to code!
- ... transport mechanisms for sharing and obtaining data
- consume and collaborate on data (analyses) like software
- ... (computationally) reproducible data analysis
- Track and share provenance of all digital objects
- ... and much more
- Completely domain-agnostic
Core concepts & features
Everything happens in DataLad datasets

Dataset = Git/git-annex repository
- content agnostic
- no custom data structures
- complete decentralization
- Looks and feels like a directory on your computer:
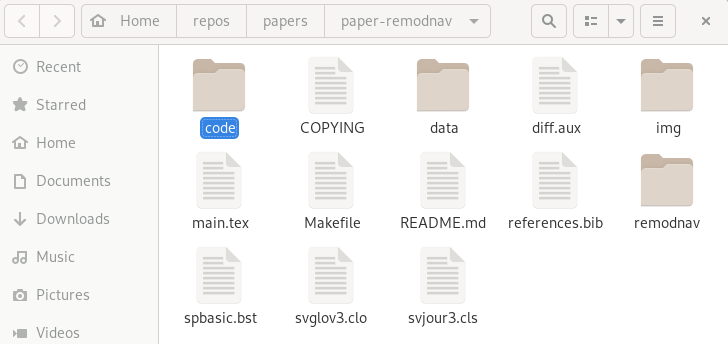
 File viewer and terminal view of a DataLad dataset
File viewer and terminal view of a DataLad dataset
version control arbitrarily large files

- Non-complex DataLad core API (easy for data management novices)
- Pure Git or git-annex commands (for regular Git or git-annex users, or to use specific functionality)
Stay flexible:
Use a datasets' history
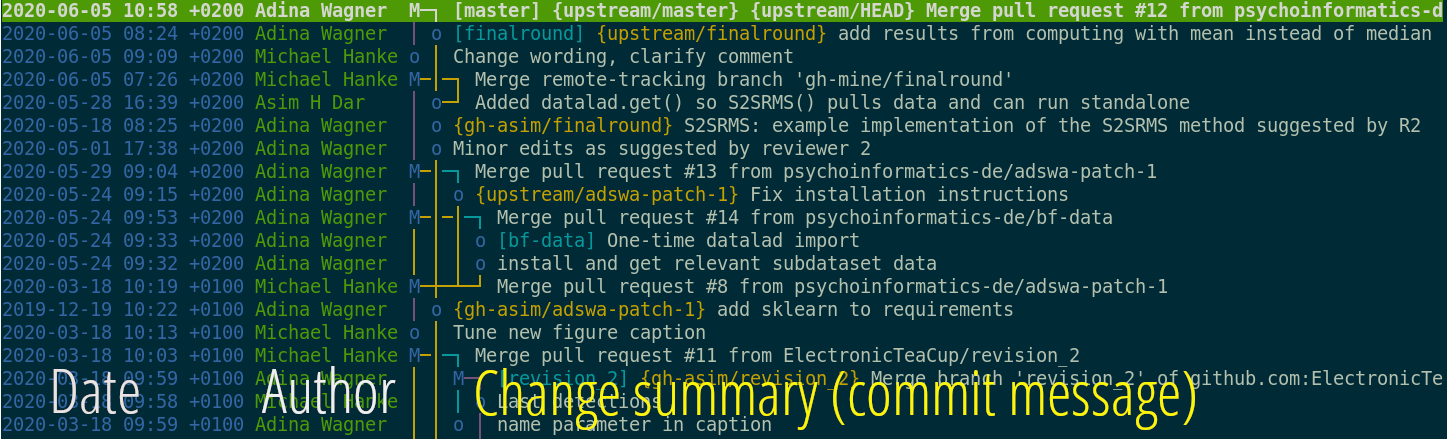
- reset your dataset (or subset of it) to a previous state,
- revert changes or bring them back,
- find out what was done when, how, why, and by whom
- Identify precise versions: Use data in the most recent version, or the one from 2018, or...
Consume and collaborate

machine-readable, re-executable provenance

Seamless nesting and dataset linkage

Third party integrations

Apart from local computing infrastructure (from private laptops to computational clusters), datasets can be hosted in major third party repository hosting and cloud storage services. More info: Chapter on Third party infrastructure.
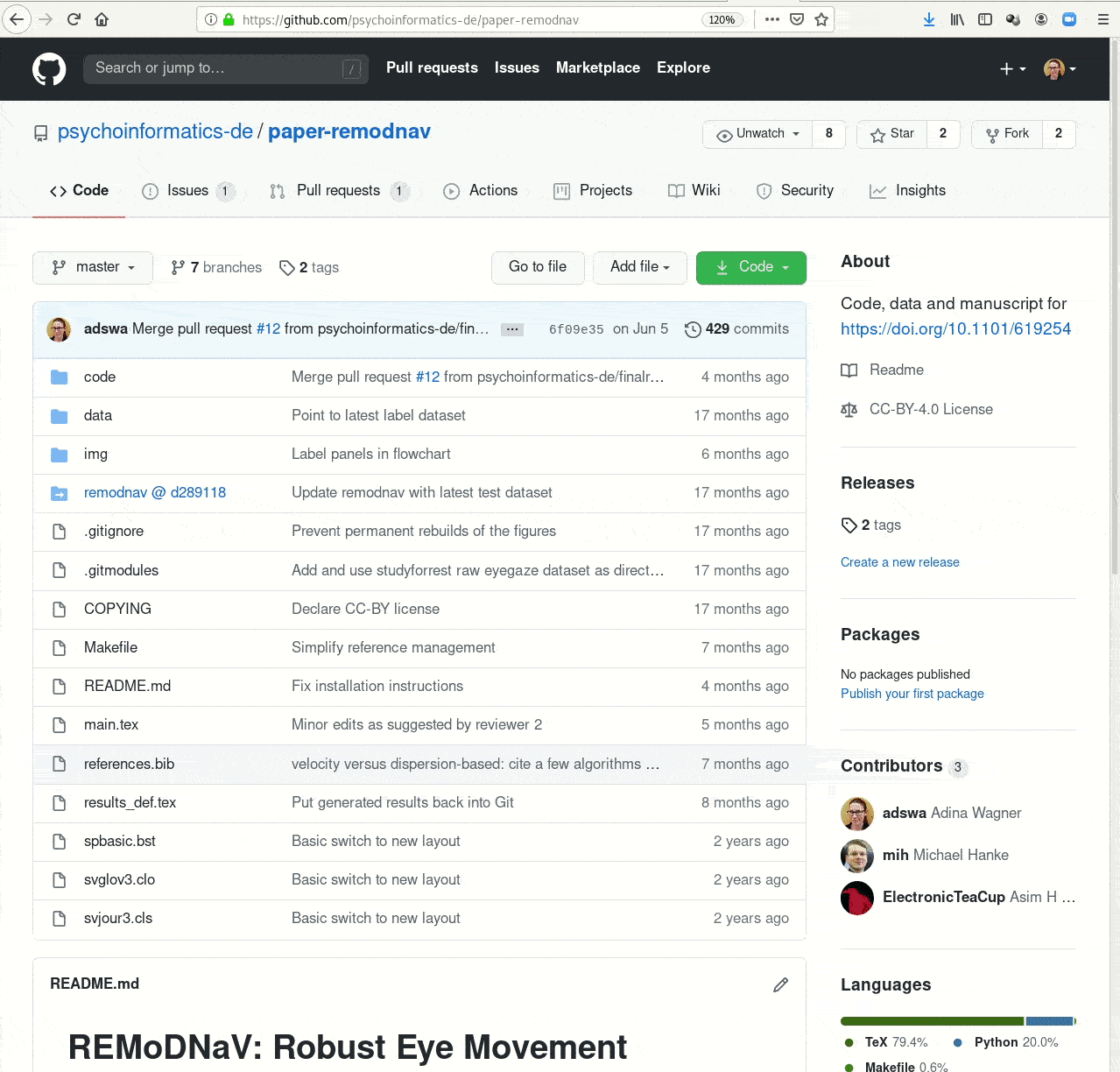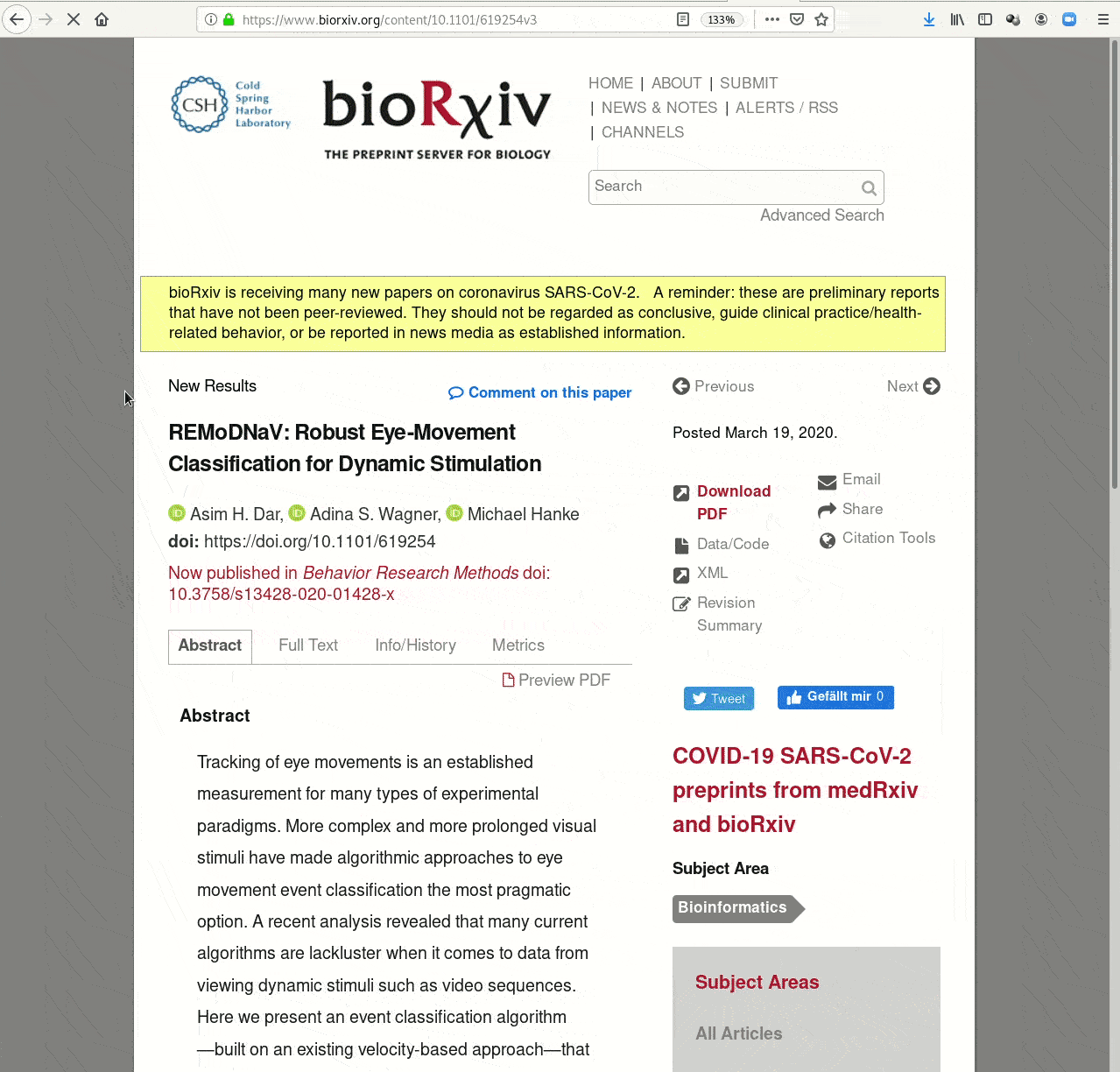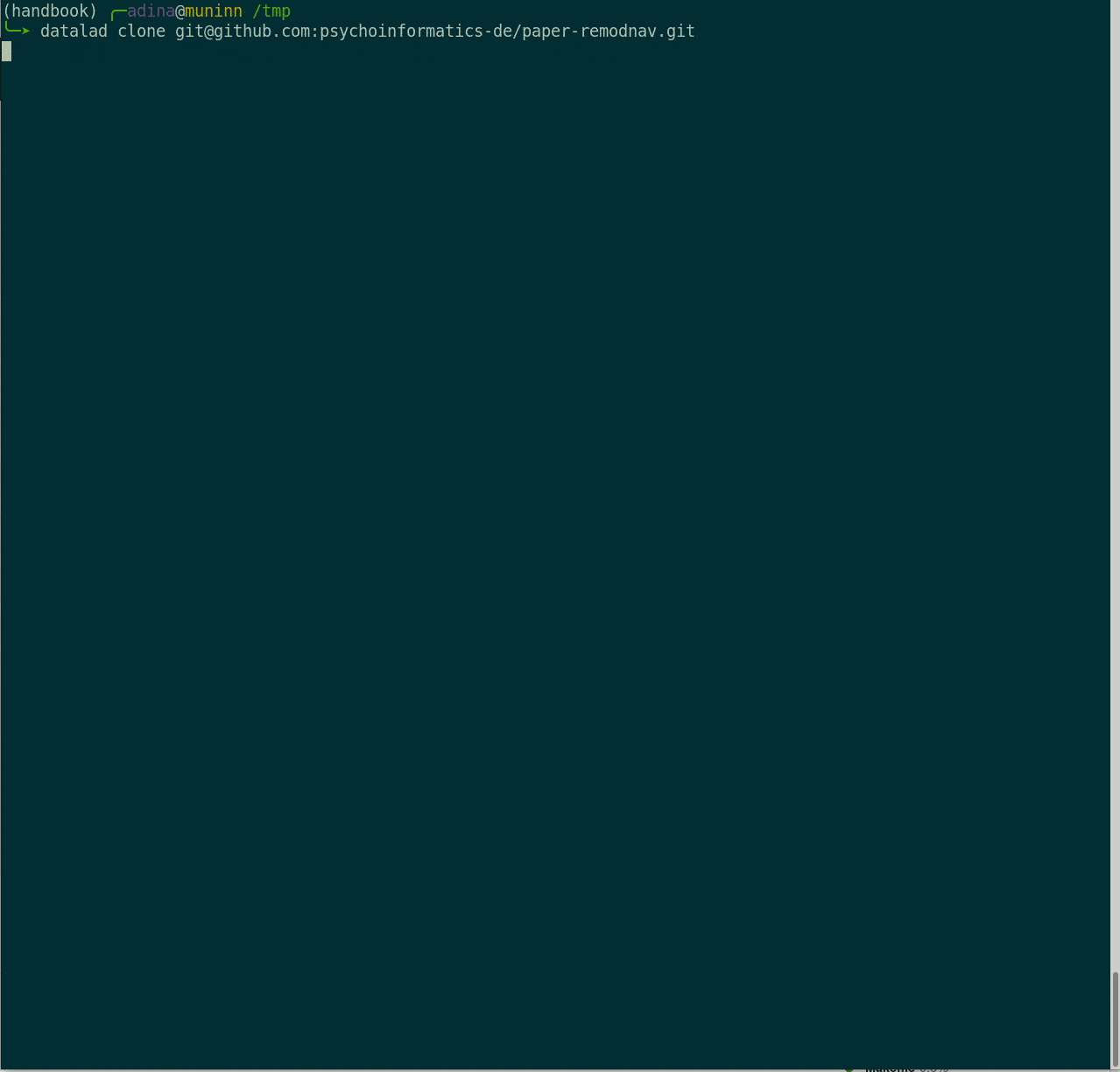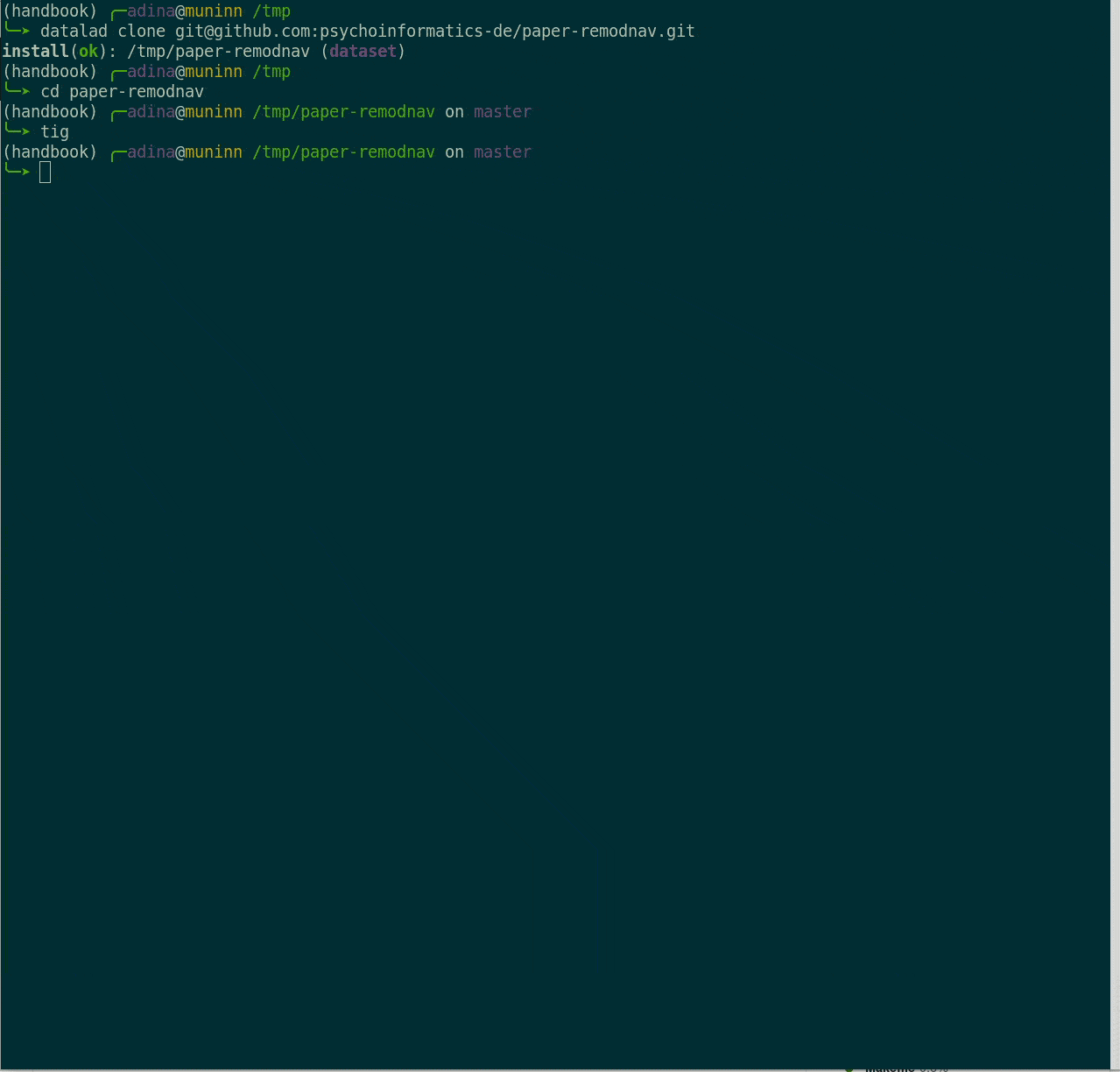
Examples of what DataLad can be used for:
- Publish or consume datasets via GitHub, GitLab, OSF, or similar services
Examples of what DataLad can be used for:
- Creating and sharing reproducible, open science: Sharing data, software, code, and provenance
Examples of what DataLad can be used for:
- Central data management and archival system
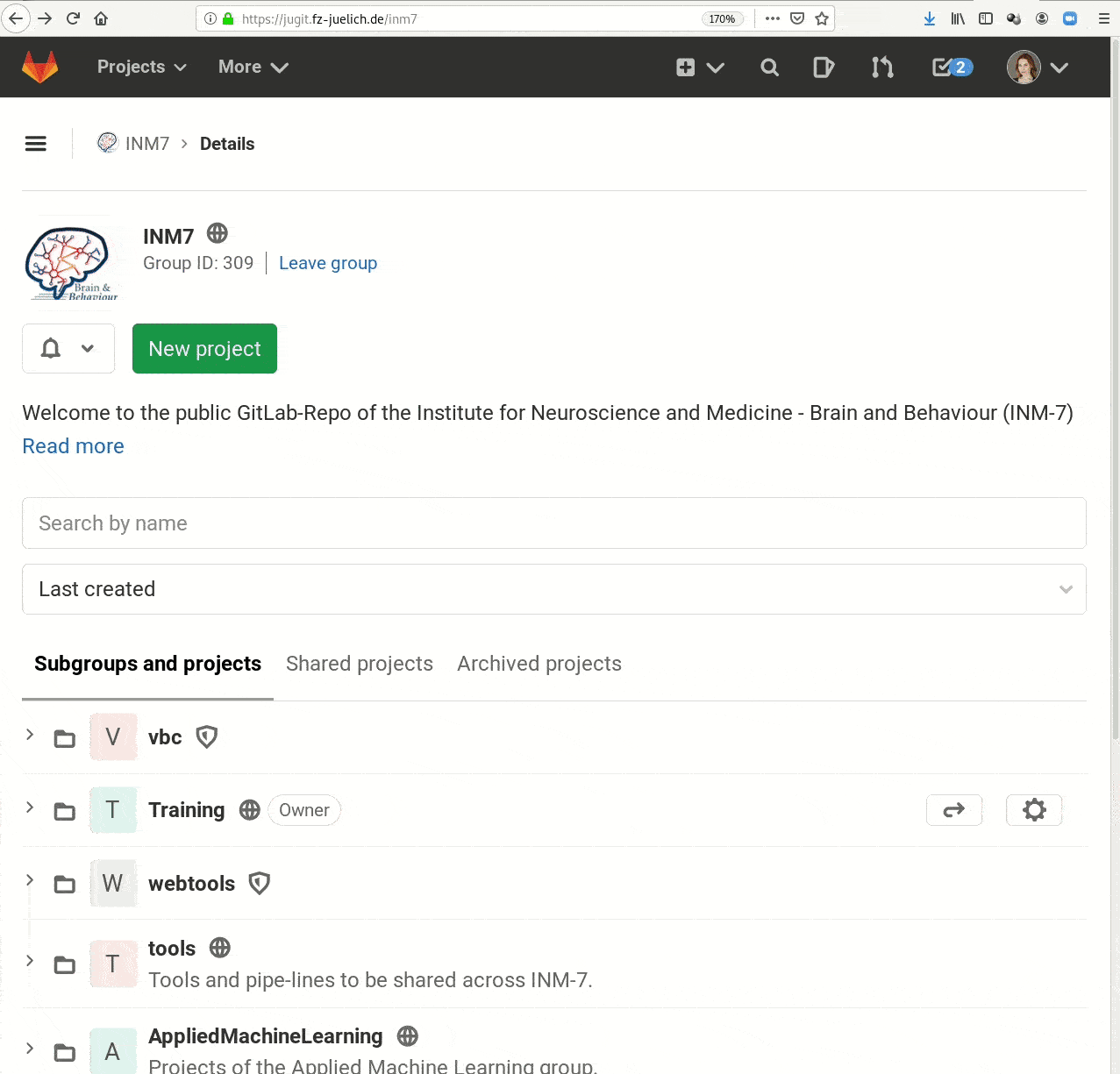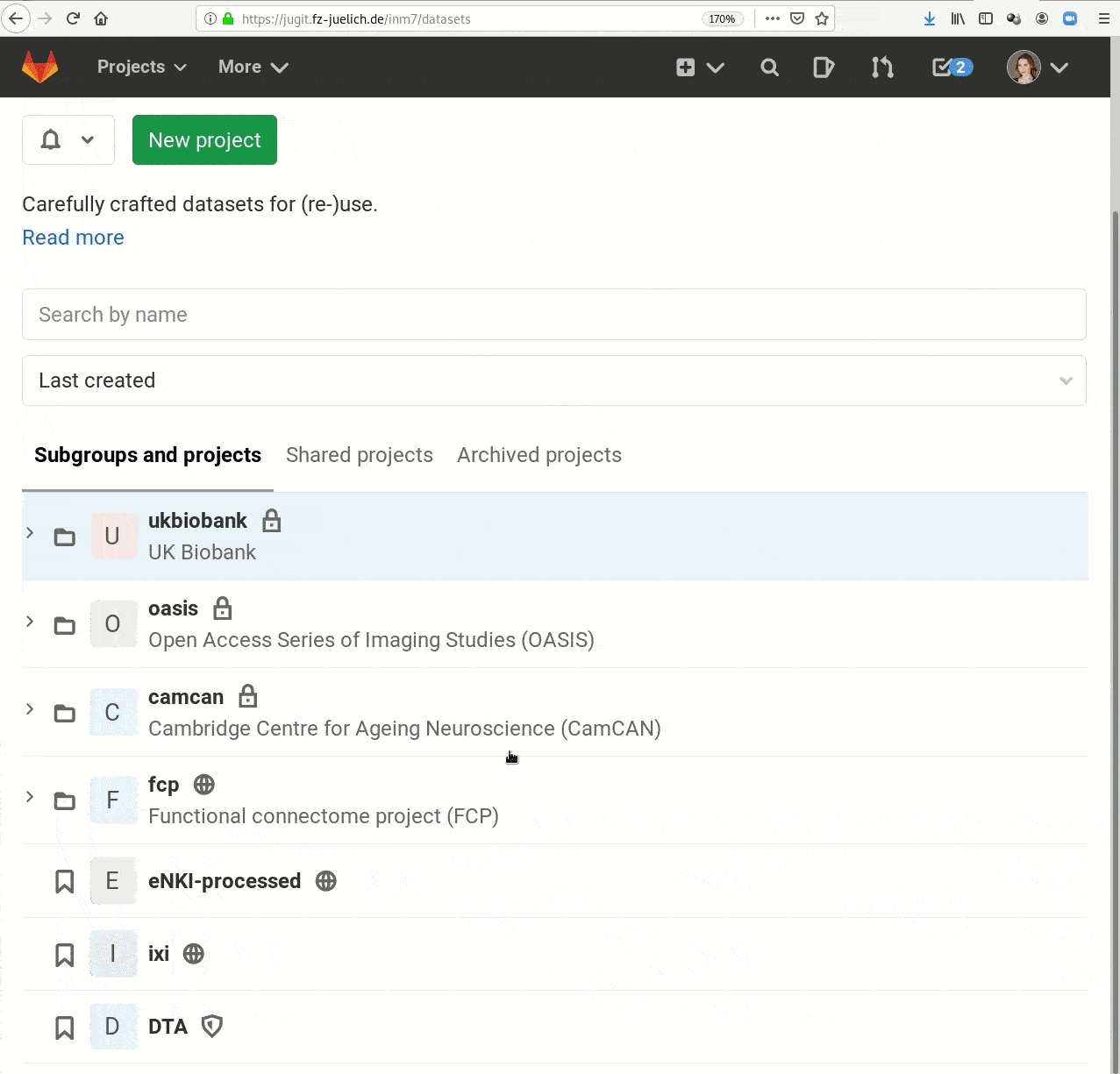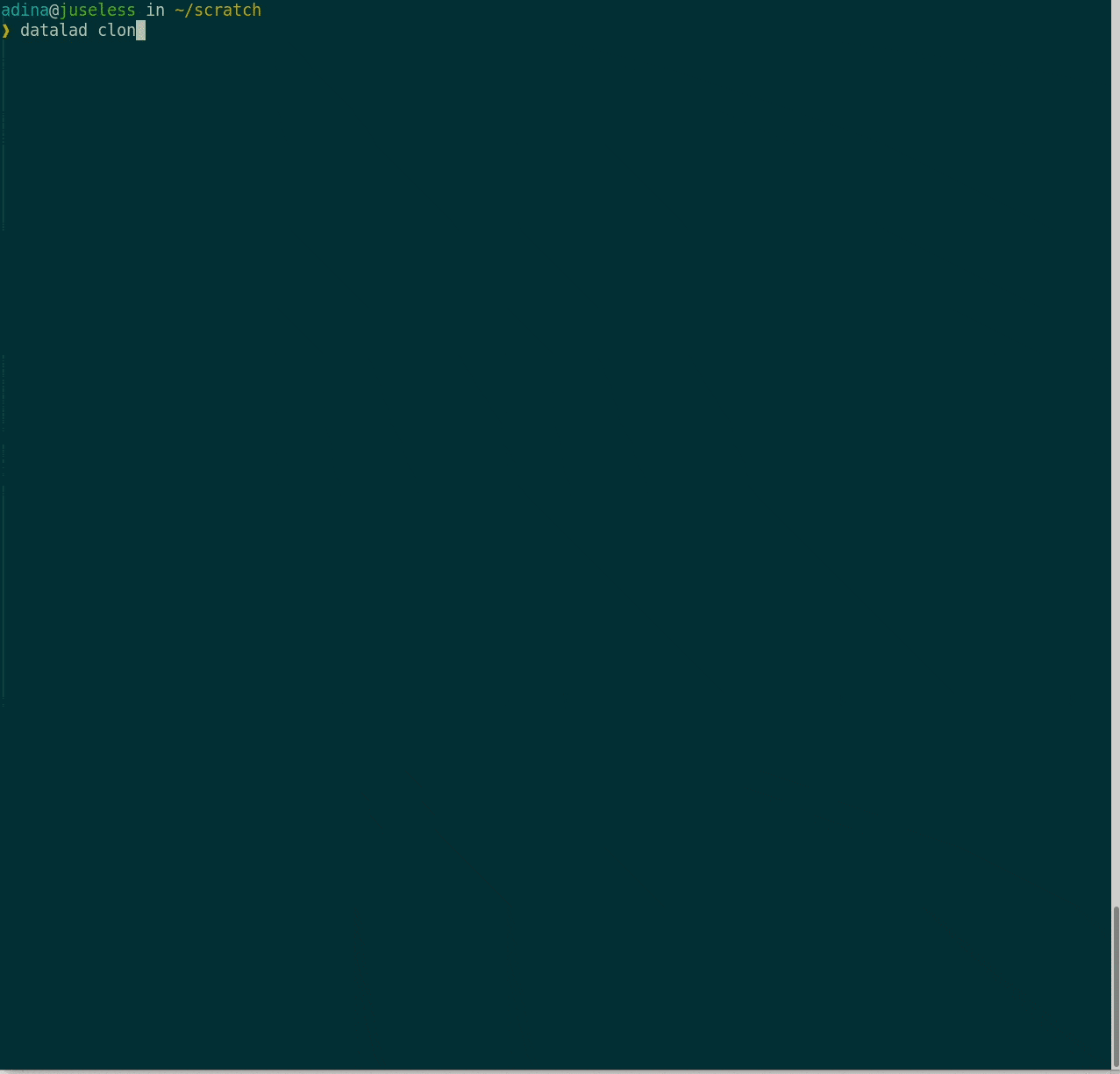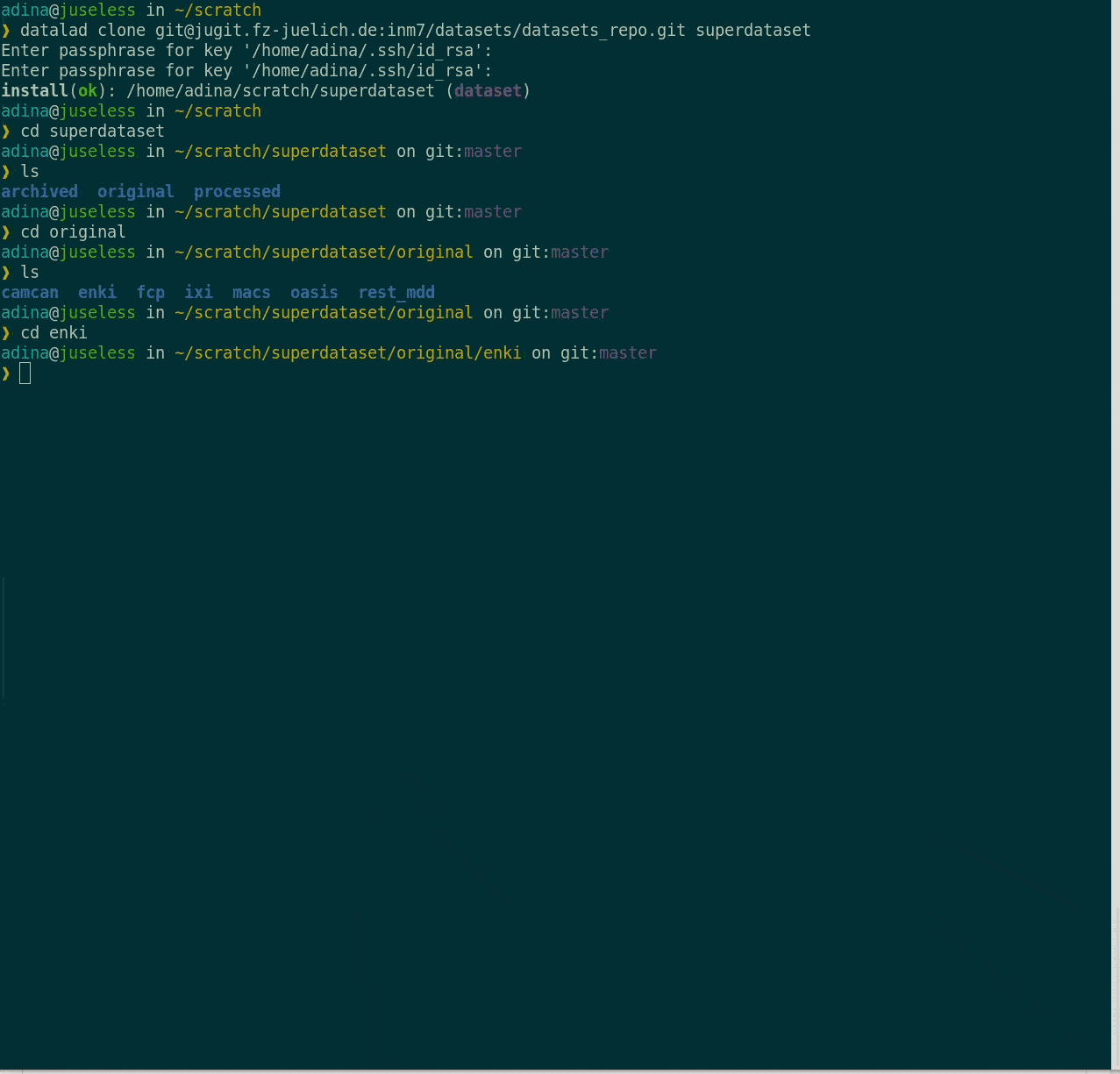
Live demo Basics
Code to follow along: handbook.datalad.org/r.html?FZJmlcodeDataLad Datasets
- DataLad's core data structure
- Dataset = A directory managed by DataLad
- Any directory of your computer can be managed by DataLad.
- Datasets can be created (from scratch) or installed
- Datasets can be nested: linked subdirectories
Questions!
Why version control?

- keep things organized
- keep track of changes
- revert changes or go back to previous states
Version Control
- DataLad knows two things: Datasets and files
Local version control
Procedurally, version control is easy with DataLad!

Advice:
- Save meaningful units of change
- Attach helpful commit messages
Summary - Local version control
datalad createcreates an empty dataset.- Configurations (-c yoda, -c text2git) are useful (details soon).
- A dataset has a history to track files and their modifications.
- Explore it with Git (git log) or external tools (e.g., tig).
datalad saverecords the dataset or file state to the history.- Concise commit messages should summarize the change for future you and others.
datalad download-urlobtains web content and records its origin.- It even takes care of saving the change.
datalad statusreports the current state of the dataset.- A clean dataset status (no modifications, not untracked files) is good practice.
Questions!
Consuming datasets
- Here's how a dataset looks after installation:
- Datasets are light-weight: Upon installation, only small files and meta data about file availability are retrieved.
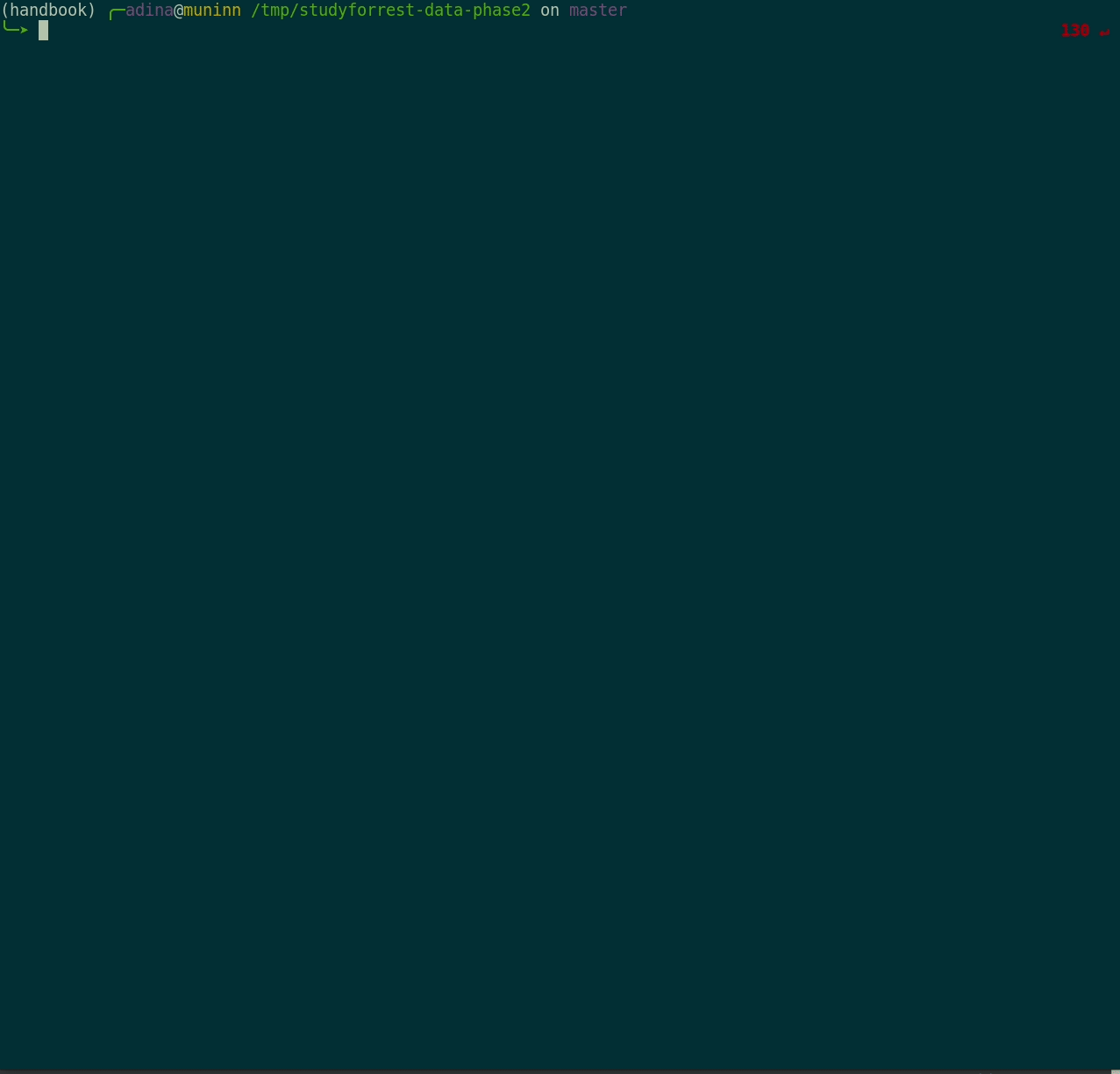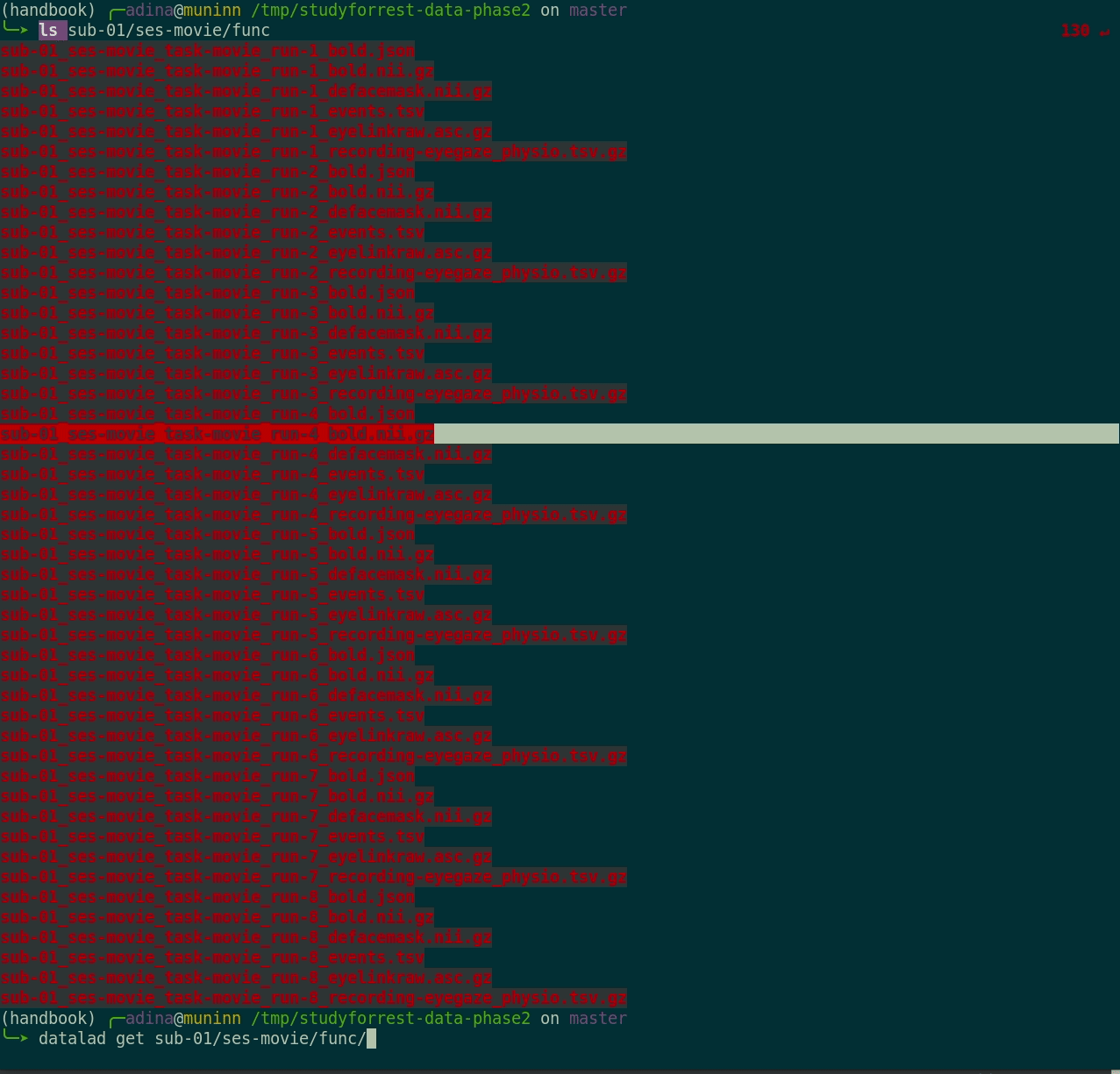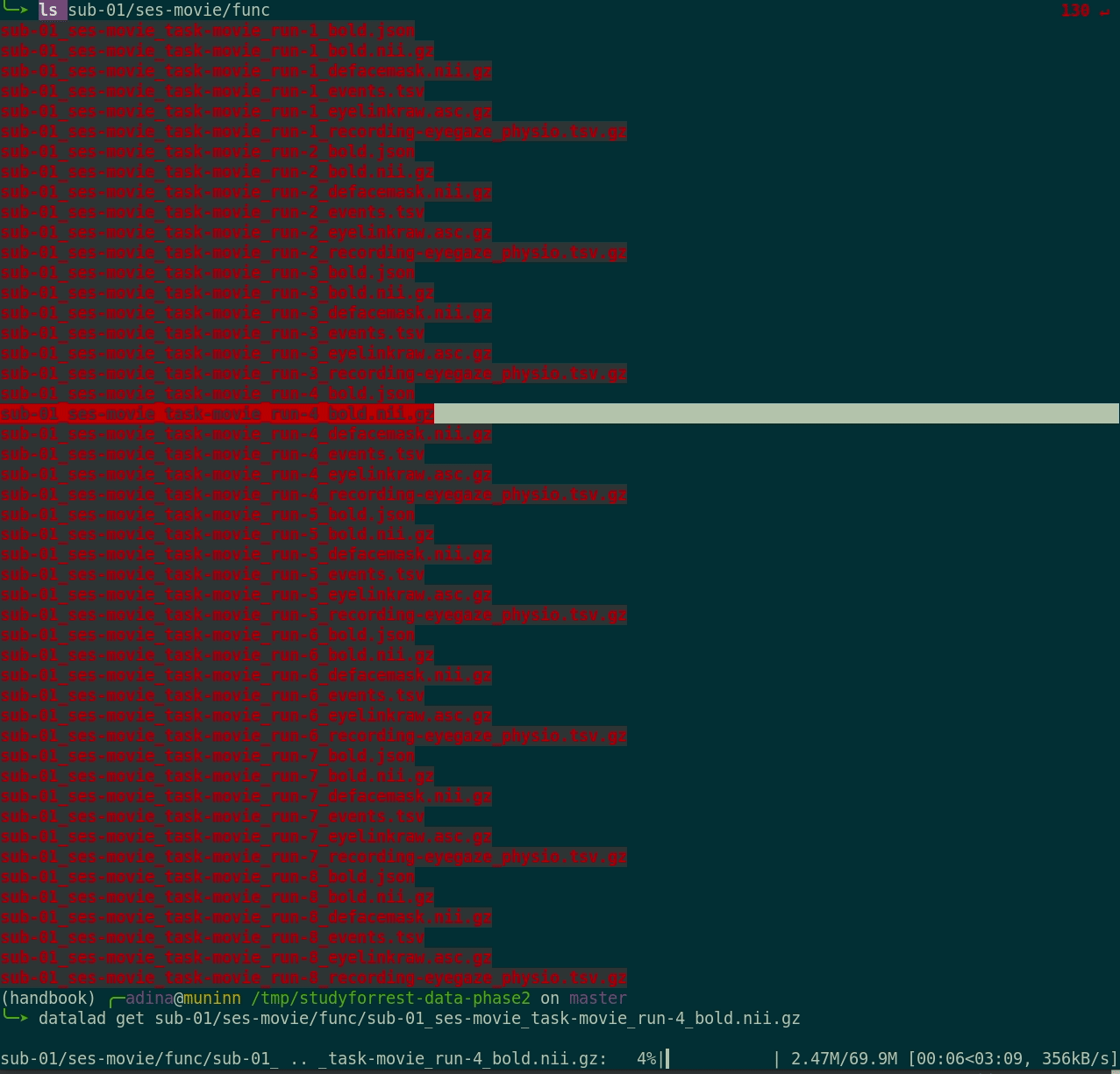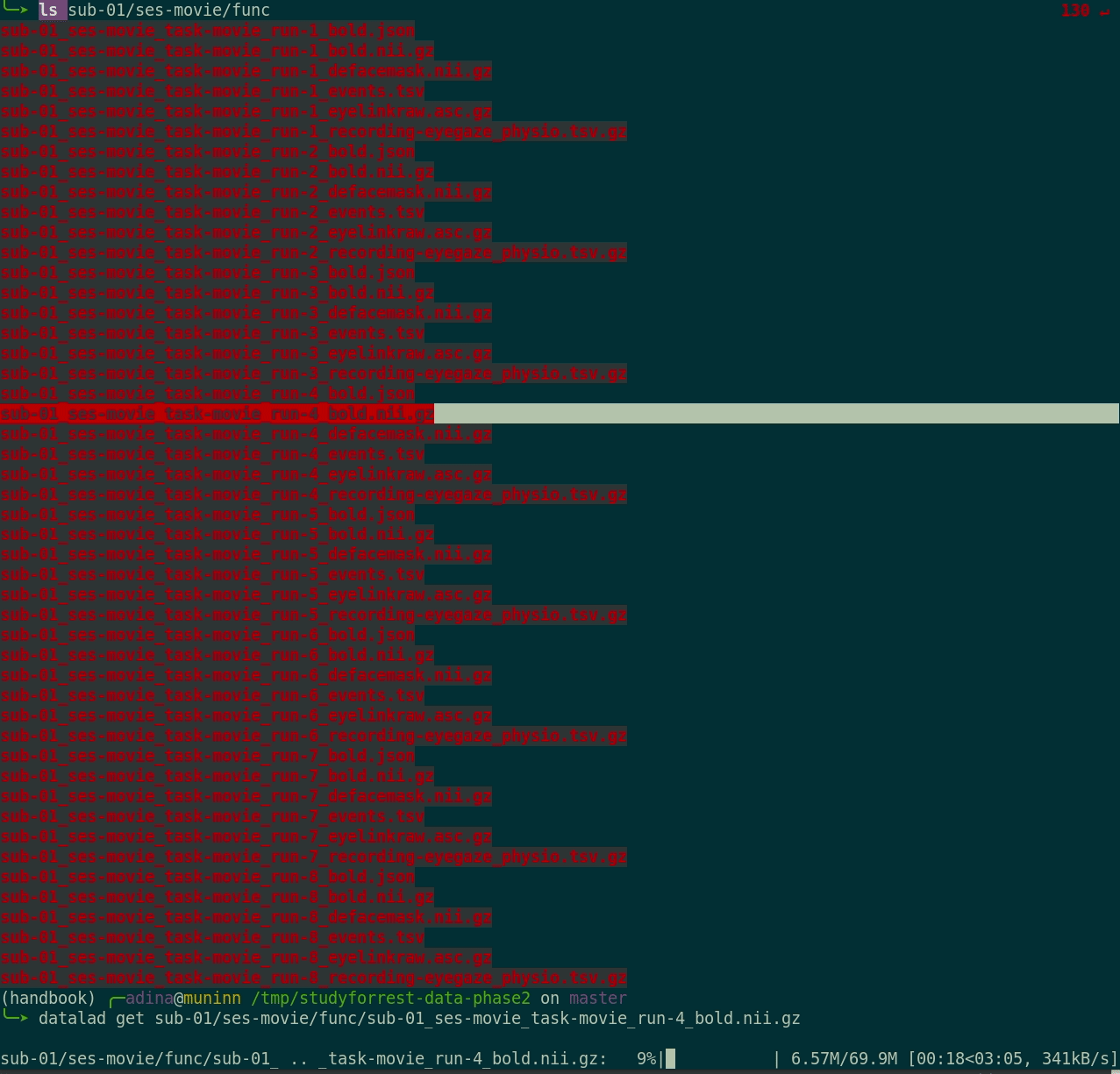
Plenty of data, but little disk-usage
- Cloned datasets are lean. "Meta data" (file names, availability) are present, but no file content:
$ datalad clone git@github.com:psychoinformatics-de/studyforrest-data-phase2.git
install(ok): /tmp/studyforrest-data-phase2 (dataset)
$ cd studyforrest-data-phase2 && du -sh
18M .$ datalad get sub-01/ses-movie/func/sub-01_ses-movie_task-movie_run-1_bold.nii.gz
get(ok): /tmp/studyforrest-data-phase2/sub-01/ses-movie/func/sub-01_ses-movie_task-movie_run-1_bold.nii.gz (file) [from mddatasrc...]# eNKI dataset (1.5TB, 34k files):
$ du -sh
1.5G .
# HCP dataset (80TB, 15 million files)
$ du -sh
48G .
Git versus Git-annex
- Data in datasets is either stored in Git or git-annex
- By default, everything is annexed, i.e., stored in a dataset annex by git-annex
| Git | git-annex |
| handles small files well (text, code) | handles all types and sizes of files well |
| file contents are in the Git history and will be shared upon git/datalad push | file contents are in the annex. Not necessarily shared |
| Shared with every dataset clone | Can be kept private on a per-file level when sharing the dataset |
| Useful: Small, non-binary, frequently modified, need-to-be-accessible (DUA, README) files | Useful: Large files, private files |
Git versus Git-annex
Useful background information for demo later. Read this handbook chapter for detailsGit and Git-annex handle files differently: annexed files are stored in an annex. File content is hashed & only content-identity is committed to Git.
- Files stored in Git are modifiable, files stored in Git-annex are content-locked
- Annexed contents are not available right after cloning, only content- and availability information (as they are stored in Git)
|
|

|
Git versus Git-annex
-
When sharing datasets with someone without access to the same computational
infrastructure, annexed data is not necessarily stored together with the rest
of the dataset.
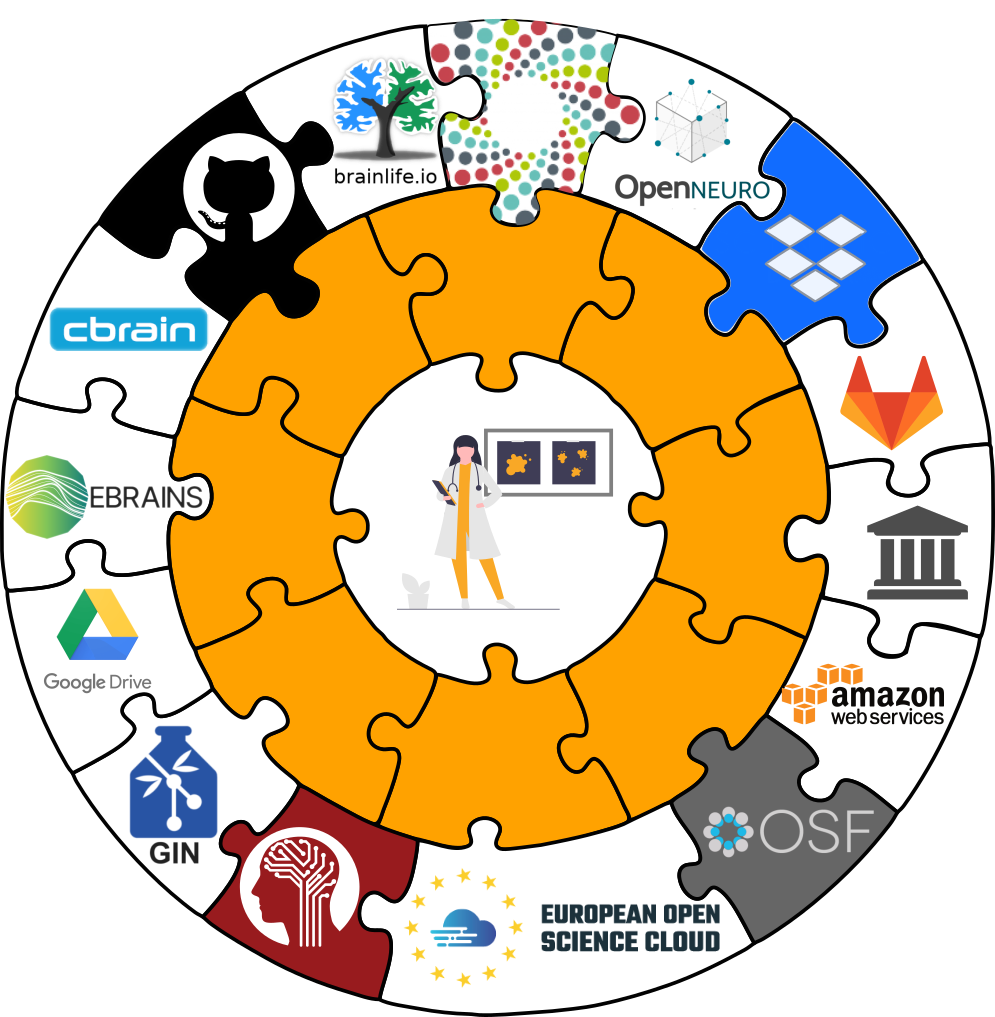
-
Transport logistics exist to interface with all major storage providers.
If the one you use isn't supported, let us know!
Git versus Git-annex
-
Users can decide which files are annexed:
- Pre-made run-procedures, provided by DataLad (e.g.,
text2git,yoda) or created and shared by users (Tutorial) - Self-made configurations in
.gitattributes(e.g., based on file type, file/path name, size, ...; rules and examples ) - Per-command basis (e.g., via
datalad save --to-git)
Dataset nesting
- Seamless nesting mechanisms:
- Overcomes scaling issues with large amounts of files
adina@bulk1 in /ds/hcp/super on git:master❱ datalad status --annex -r
15530572 annex'd files (77.9 TB recorded total size)
nothing to save, working tree cleanDataset nesting

Summary - Dataset consumption & nesting
datalad cloneinstalls a dataset.- It can be installed “on its own”: Specify the source (url, path, ...) of the dataset, and an optional path for it to be installed to.
- Datasets can be installed as subdatasets within an existing dataset.
- The --dataset/-d option needs a path to the root of the superdataset.
- Only small files and metadata about file availability are present locally after an install.
- To retrieve actual file content of annexed files,
datalad getdownloads file content on demand. - Datasets preserve their history.
- The superdataset records only the version state of the subdataset.
Questions!
reproducible data analysis
Your past self is the worst collaborator:
Basic organizational principles for datasets
- Keep everything clean and modular
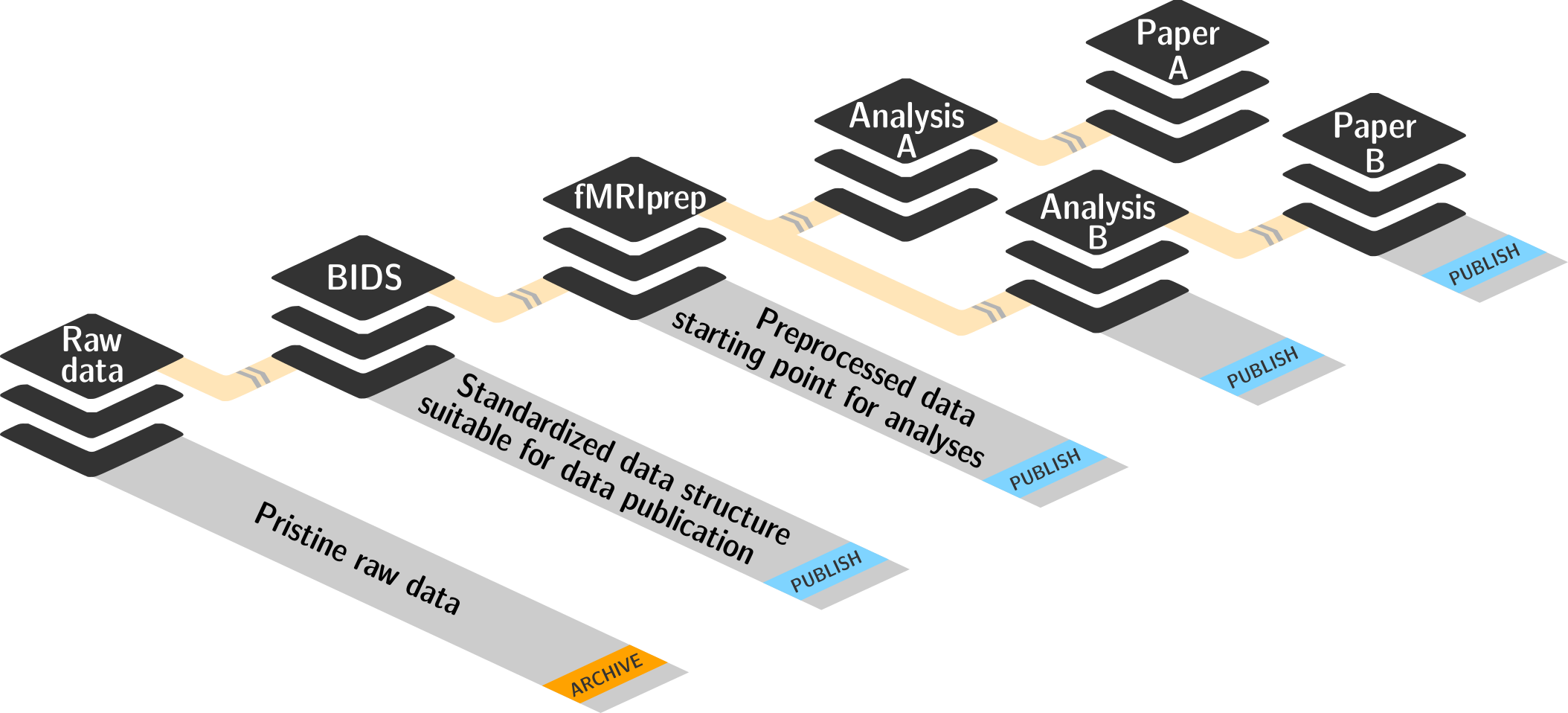 |
|
- do not touch/modify raw data: save any results/computations outside of input datasets
- Keep a superdataset self-contained: Scripts reference subdatasets or files with relative paths
Basic organizational principles for datasets
- Record where you got it from, where it is now, and what you do to it

- Document everything:
A classification analysis on the iris flower dataset

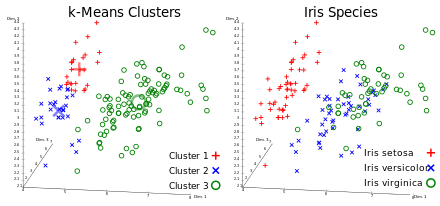
Reproducible execution & provenance capture
datalad run

Computational reproducibility
- Code may fail (to reproduce) if run with different software
- Datasets can store (and share) software environments (Docker or Singularity containers) and reproducibly execute code inside of the software container, capturing software as additional provenance
- DataLad extension:
datalad-container
datalad-containers run

Summary - Reproducible execution
datalad runrecords a command and its impact on the dataset.- All dataset modifications are saved - use it in a clean dataset.
- Data/directories specified as
--inputare retrieved prior to command execution. - Use one flag per input.
- Data/directories specified as
--outputwill be unlocked for modifications prior to a rerun of the command. - Its optional to specify, but helpful for recomputations.
datalad containers-runcan be used to capture the software environment as provenance.- Its ensures computations are ran in the desired software set up. Supports Docker and Singularity containers
datalad reruncan automatically re-execute run-records later.- They can be identified with any commit-ish (hash, tag, range, ...)
Questions!
A machine-learning example
Analysis layout
|
 Imagenette dataset
Imagenette dataset
|
Prepare an input dataset
- Create a stand-alone input dataset
- Either add data and
datalad saveit, or use commands such asdatalad download-urlordatalad add-urlsto retrieve it from web-sources
Configure and setup an analysis dataset
- Given the purpose of an analysis dataset, configurations can make it easier to use:
-c yodaprepares a useful structure-c text2gitkeeps text files such as scripts in Git- The input dataset is installed as a subdataset
- Required software is containerized and added to the dataset
Prepare data
- Add a script for data preparation (labels train and validation images)
- Execute it using
datalad containers-run
Train models and evaluate them
- Add scripts for training and evaluation. This dataset state can be tagged to identify it easily at a later point
- Execute the scripts using
datalad containers-run - By dumping a trained model as a joblib object the trained classifier stays reusable
Tips and tricks for ML applications
- Standalone input datasets keep input data extendable and reusable
- Subdatasets can be registered in precise versions, and updated to the newest state
- Software containers aid greatly with reproducibility
- The correct software environment is preserved and can be shared
- Re-executable run-records can capture all provenance
- This can also capture command-line parametrization
- Git workflows can be helpful elements in ML workflows
- DataLad is no workflow manager, but by checking out out tags or branches one can switch easy and fast between results of different models
Why use DataLad?
- Mistakes are not forever anymore: Easy version control, regardless of file size
- Who needs short-term memory when you can have run-records?
- Disk-usage magic: Have access to more data than your hard drive has space
- Collaboration and updating mechanisms: Alice shares her data with Bob. Alice fixes a mistake and pushes the fix. Bob says "datalad update" and gets her changes. And vice-versa.
- Transparency: Shared datasets keep their history. No need to track down a former student, ask their project what was done.
Thank you for your attention!
Questions!
More useful information
(But please ask if there's anything else you want to know)
Scalability
-
How large can datasets get?
- In general: Size is not a problem, as long as large files are handled with git-annex
- Bottle-neck: Number of files. 100-200k per dataset!
- How to scale up? Nest datasets as subdatasets
- Currently largest dataset: human connectome project data, 80TB, 15 million files, ~4500 subdataset
- Currently in the making: institute archival system, 125TB
- Currently worked towards: Processing UKBiobank data, 0.5PB
Need more information? Read the chapter on scaling up at handbook.datalad.org
Transfer existing projects
-
Can existing projects become dataset?
- In general: Yes (but make a backup, just in case)
datalad create -fcan transform any directory or Git repository into a dataset- Afterwards, untracked contents need to be saved
Need more information? Read the section on transitioning existing projects to DataLad at handbook.datalad.org
Easy storage for annex
-
How can I share annexed data fast and easy?
- In general: Dozens of services are supported via git-annex "special remote" concept, (Amazon S3, Dropbox, GDrive, private webserver...)
- Some repository hosting services also host annexed data: GIN (free, supports anonymous read access), GitHub & GitLab if used with GitLFS (non-free)
- datalad-osf extension for hosting datasets on the open science frameworf (OSF)
Need more information? Read the chapter on third party infrastructure at handbook.datalad.org
Thanks for your attention!
- Speak up now or reach out to us later with any questions