Publishing data
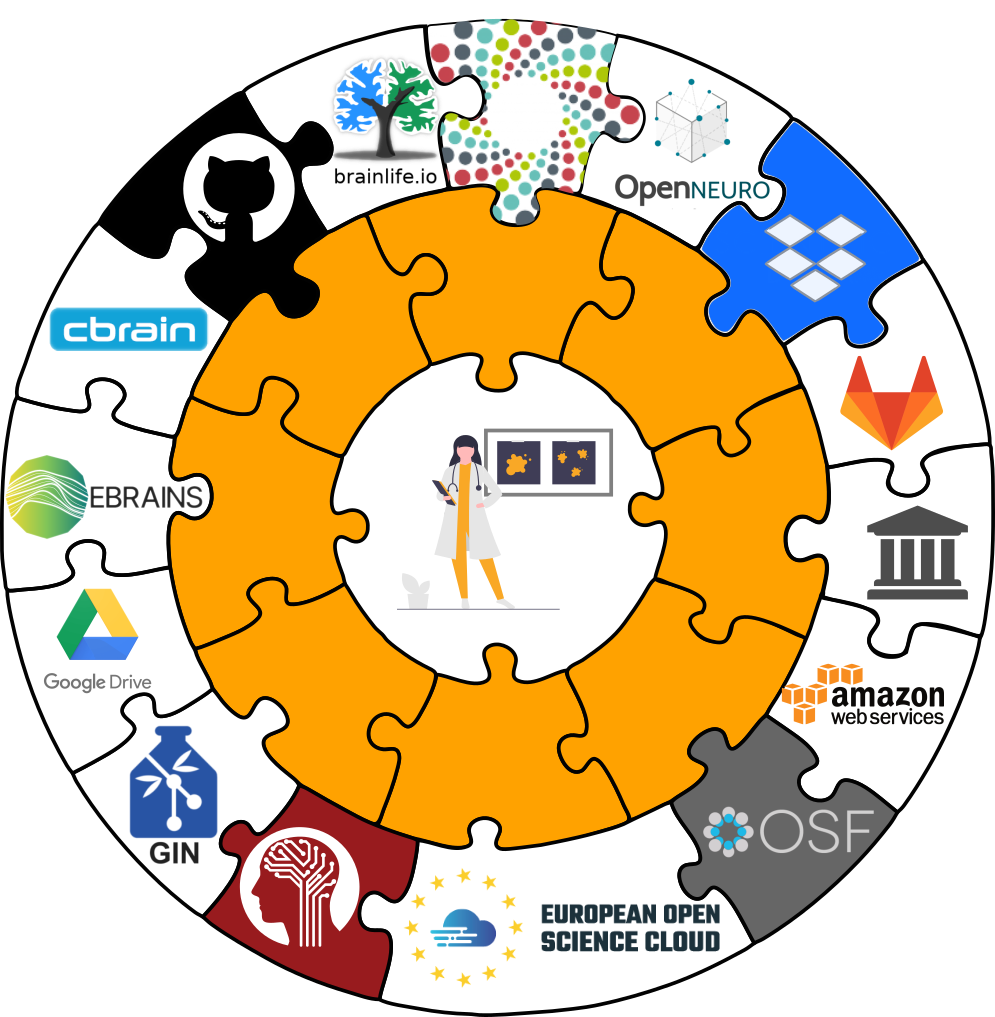
Transport logistics
- Share data like source code
- Datasets can be cloned, pushed, and updated from and to local paths, remote hosting services, external special remotes

- Flexible data access management for annexed file contents based on storage location
Interoperability
- DataLad is built to maximize interoperability and use with hosting and storage technology
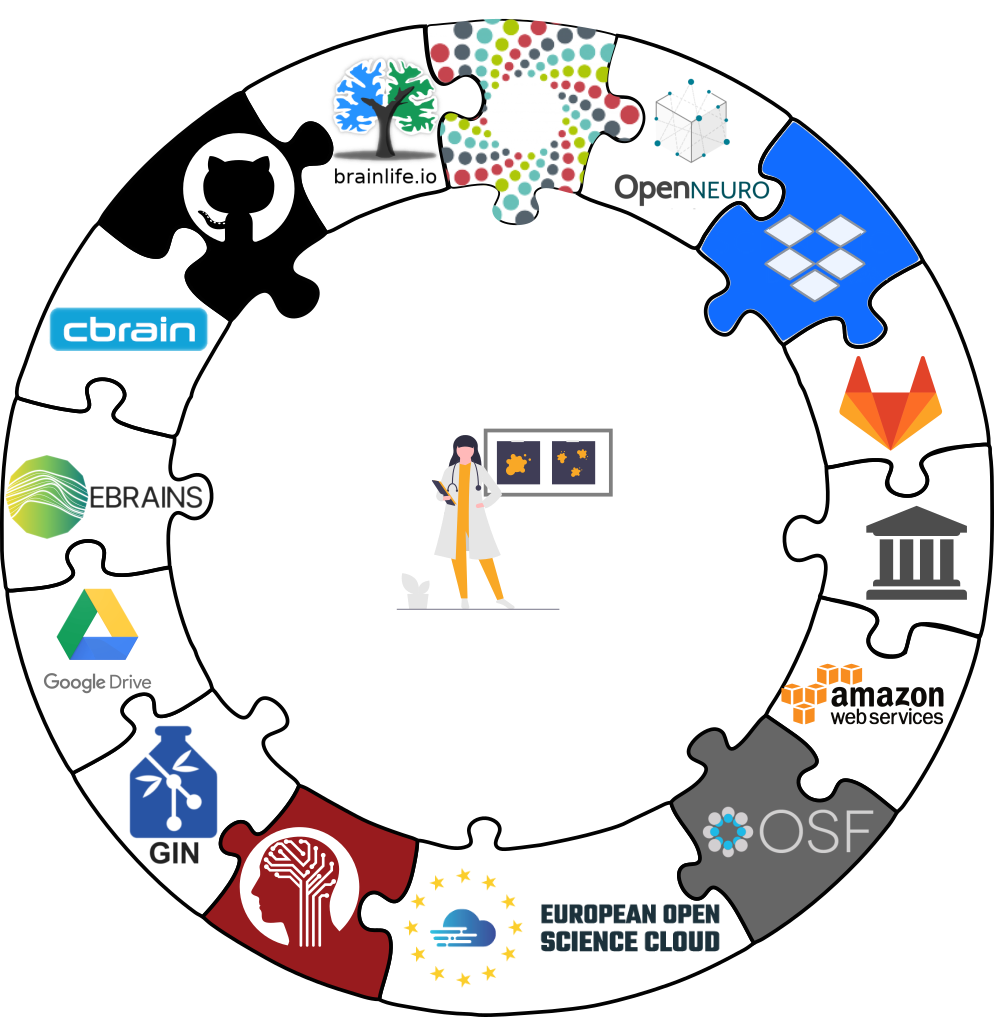
Interoperability
- DataLad is built to maximize interoperability and use with hosting and storage technology
Publishing datasets
I have a dataset on my computer. How can I share it, or collaborate on it?
Publishing datasets
- Most public datasets separate content in Git versus git-annex behind the scenes

Publishing datasets

Publishing datasets

Publishing datasets
Typical case:- Datasets are exposed via a private or public repository on a repository hosting service
- Data can't be stored in the repository hosting service, but can be kept in almost any third party storage
- Publication dependencies automate pushing to the correct place

Publishing datasets
$ git config --local remote.github.datalad-publish-depends gdrive Publishing datasets
- Real-life example:
Publishing datasets
Special case 1: repositories with annex support
Publishing datasets
Special case 2: Special remotes with repositories
Publishing datasets
Special case 1: repositories with annex support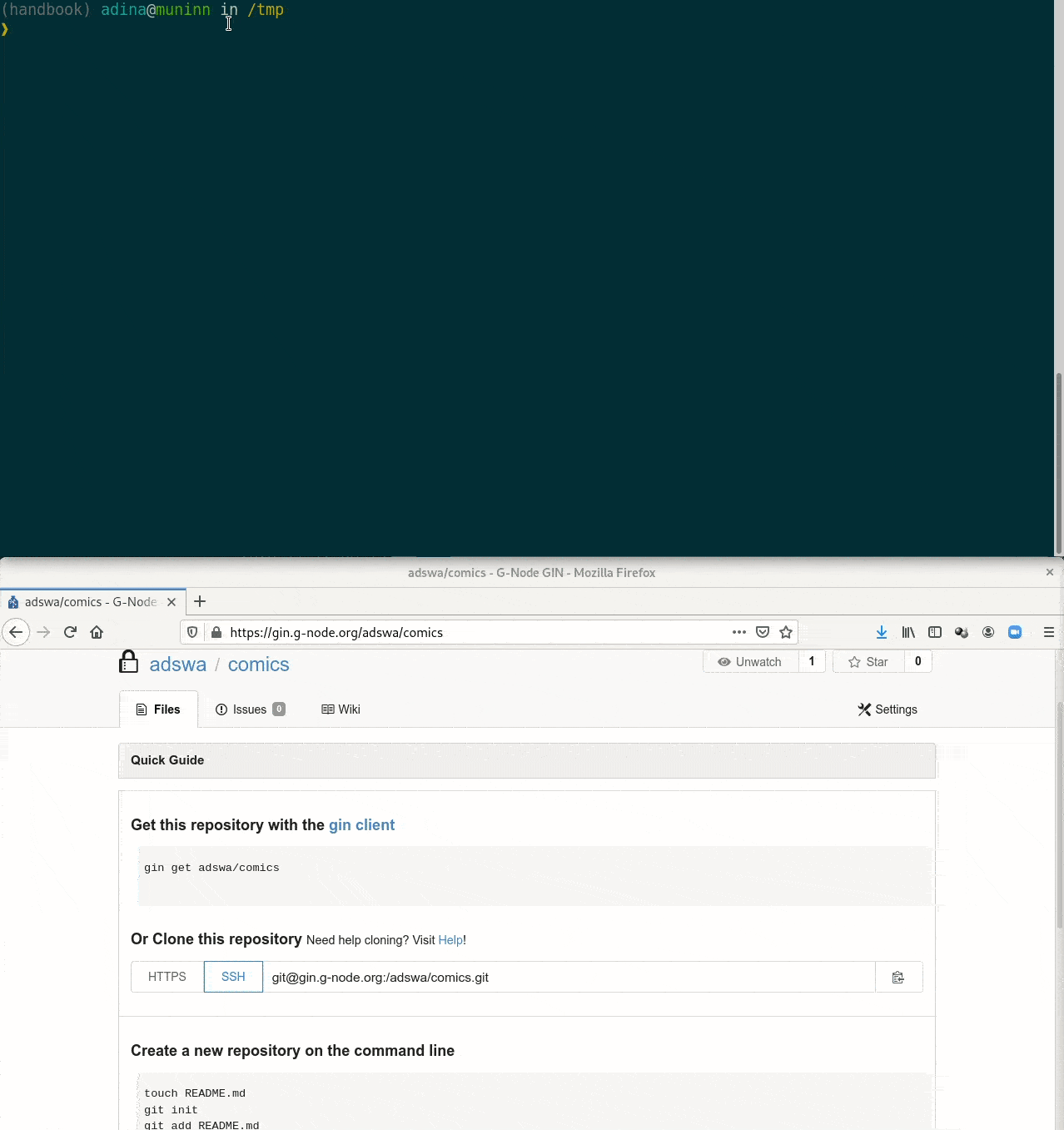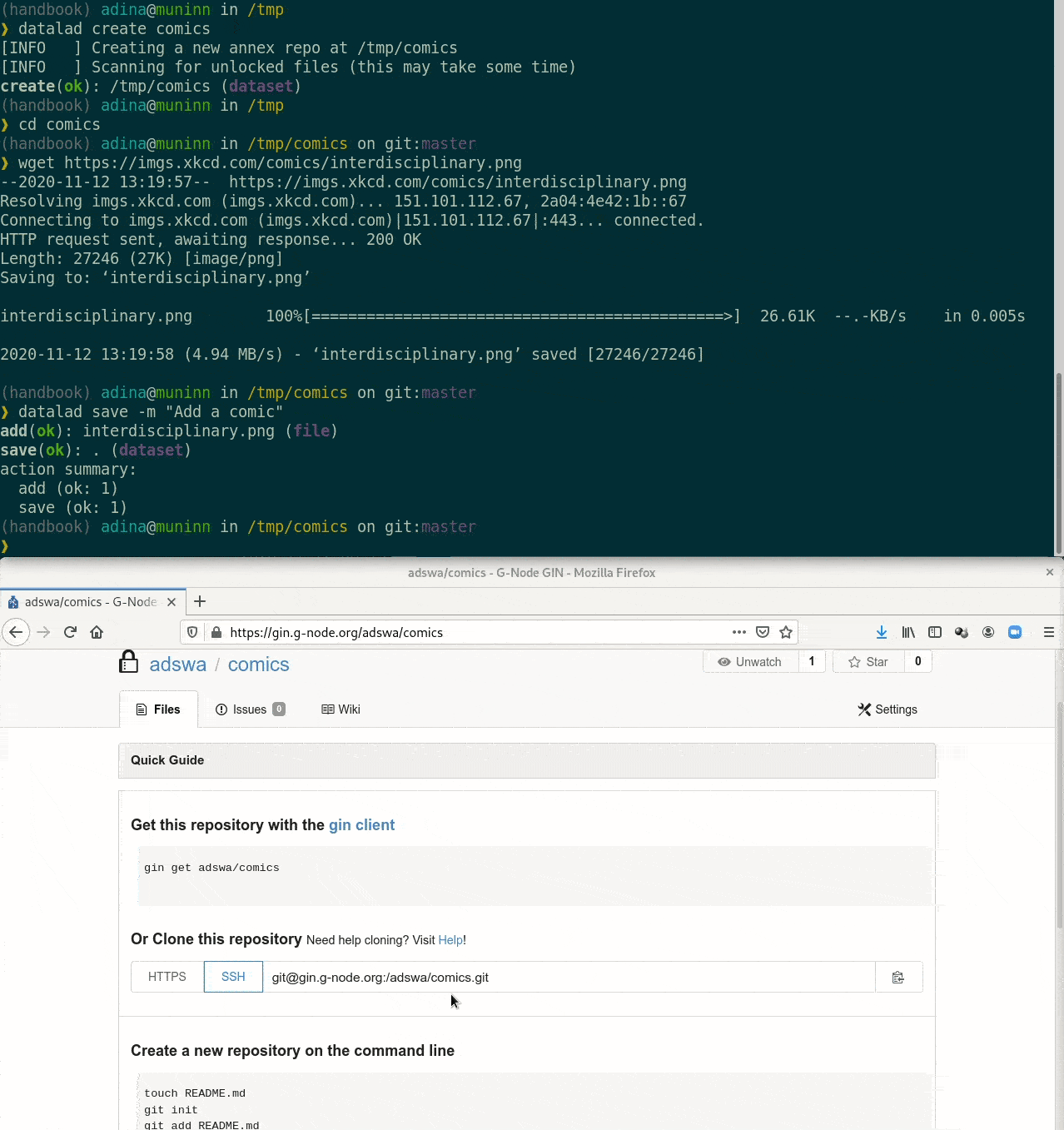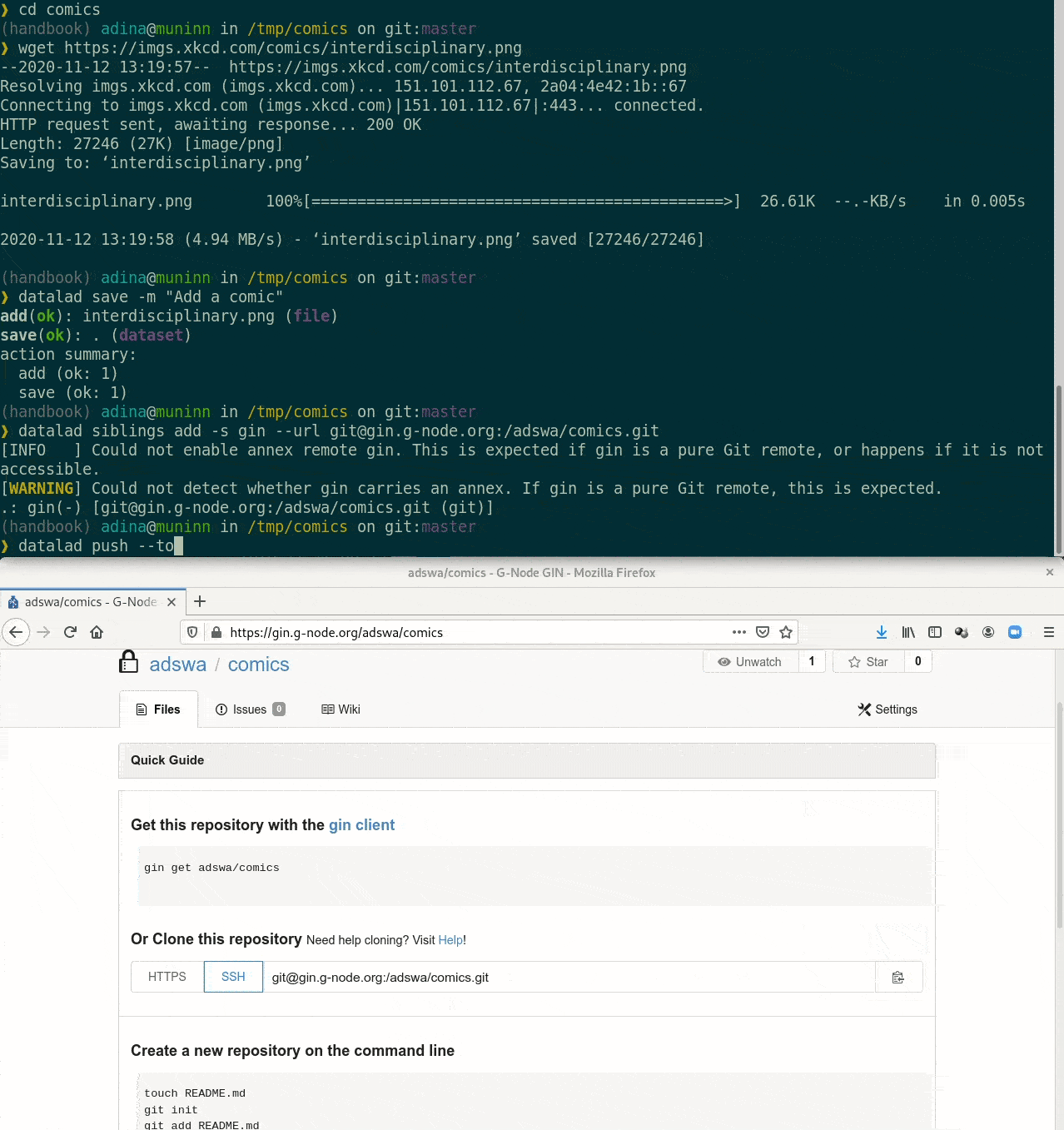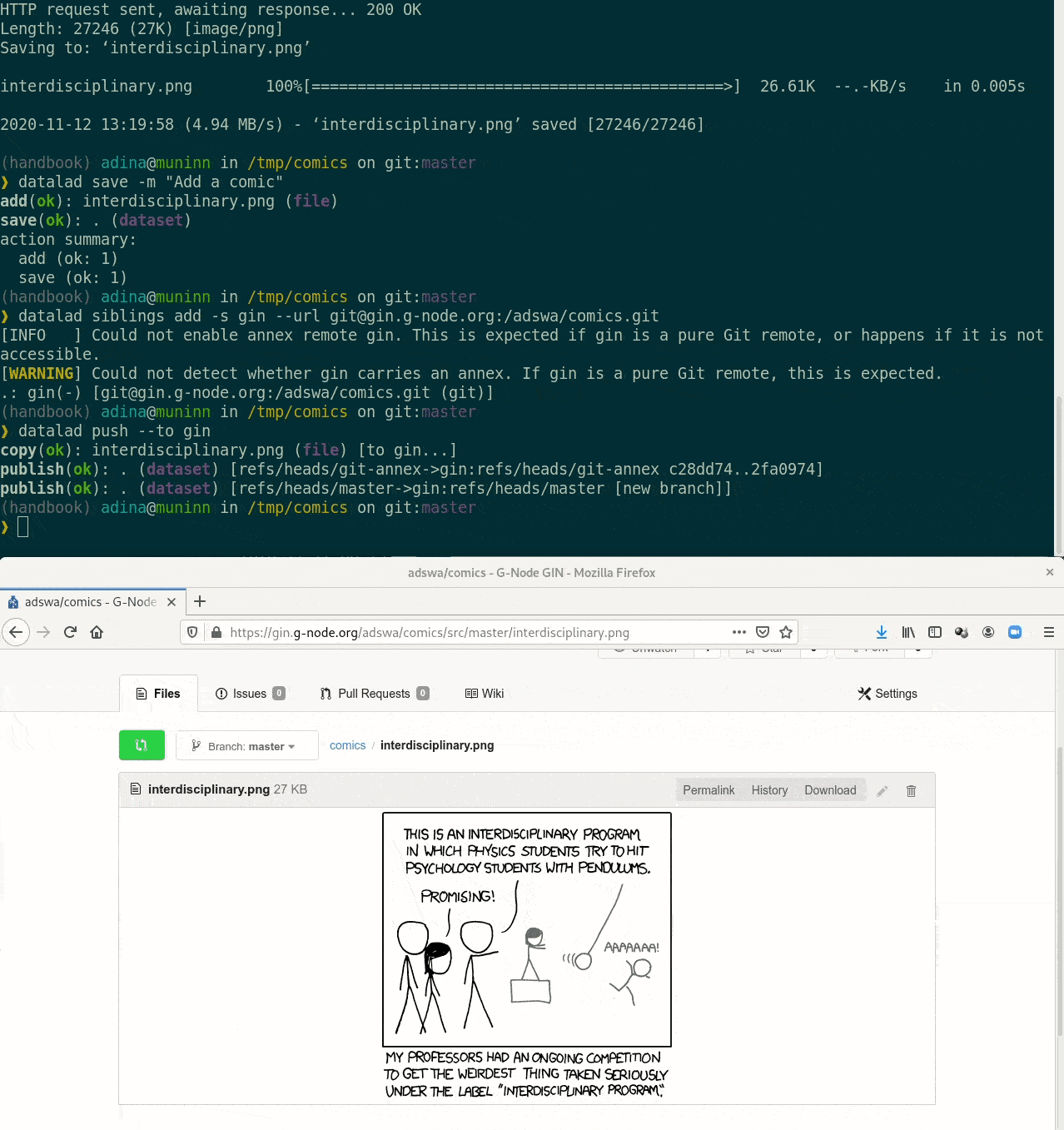
Publishing datasets
Special case 2: Special remotes with repositories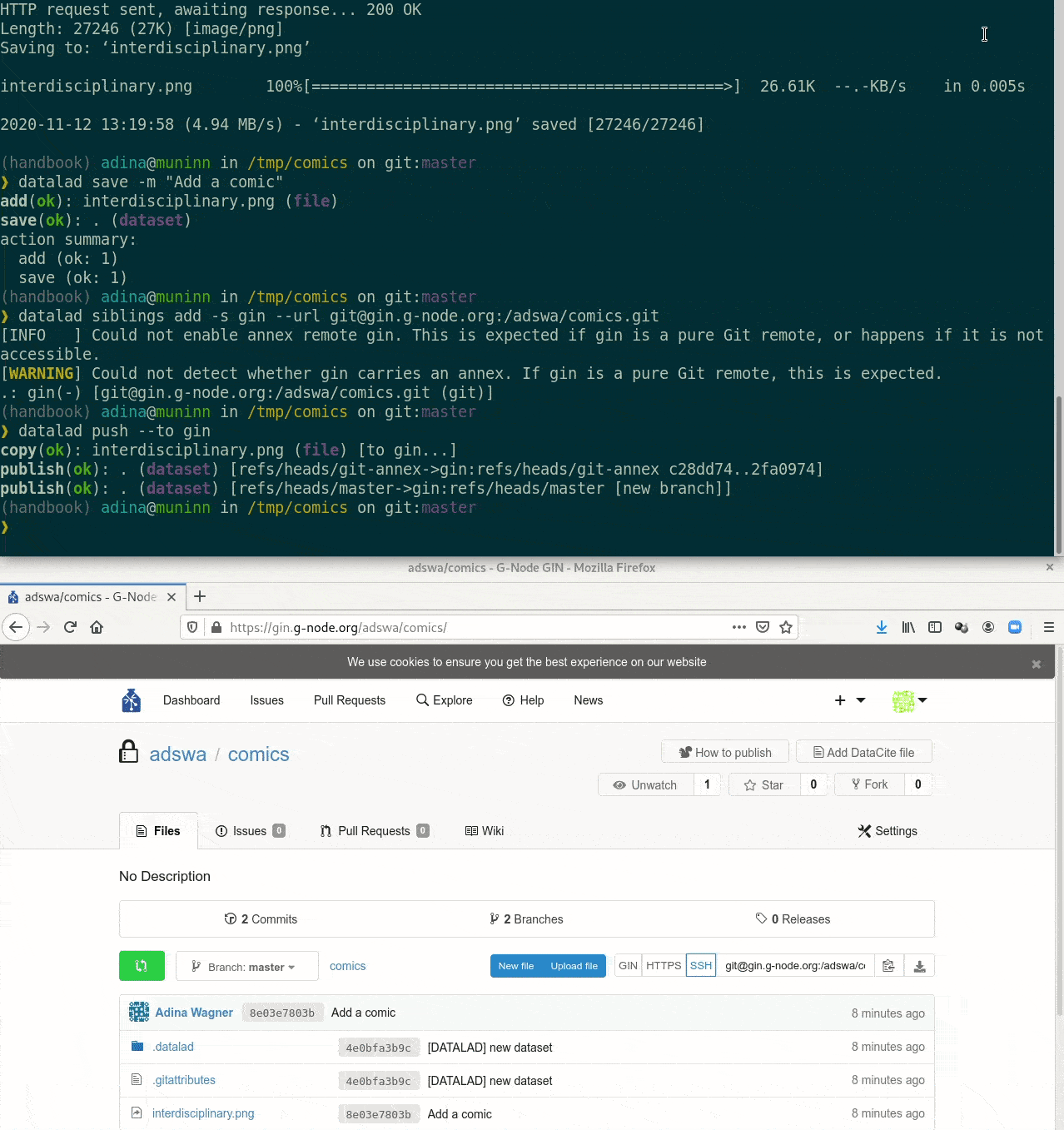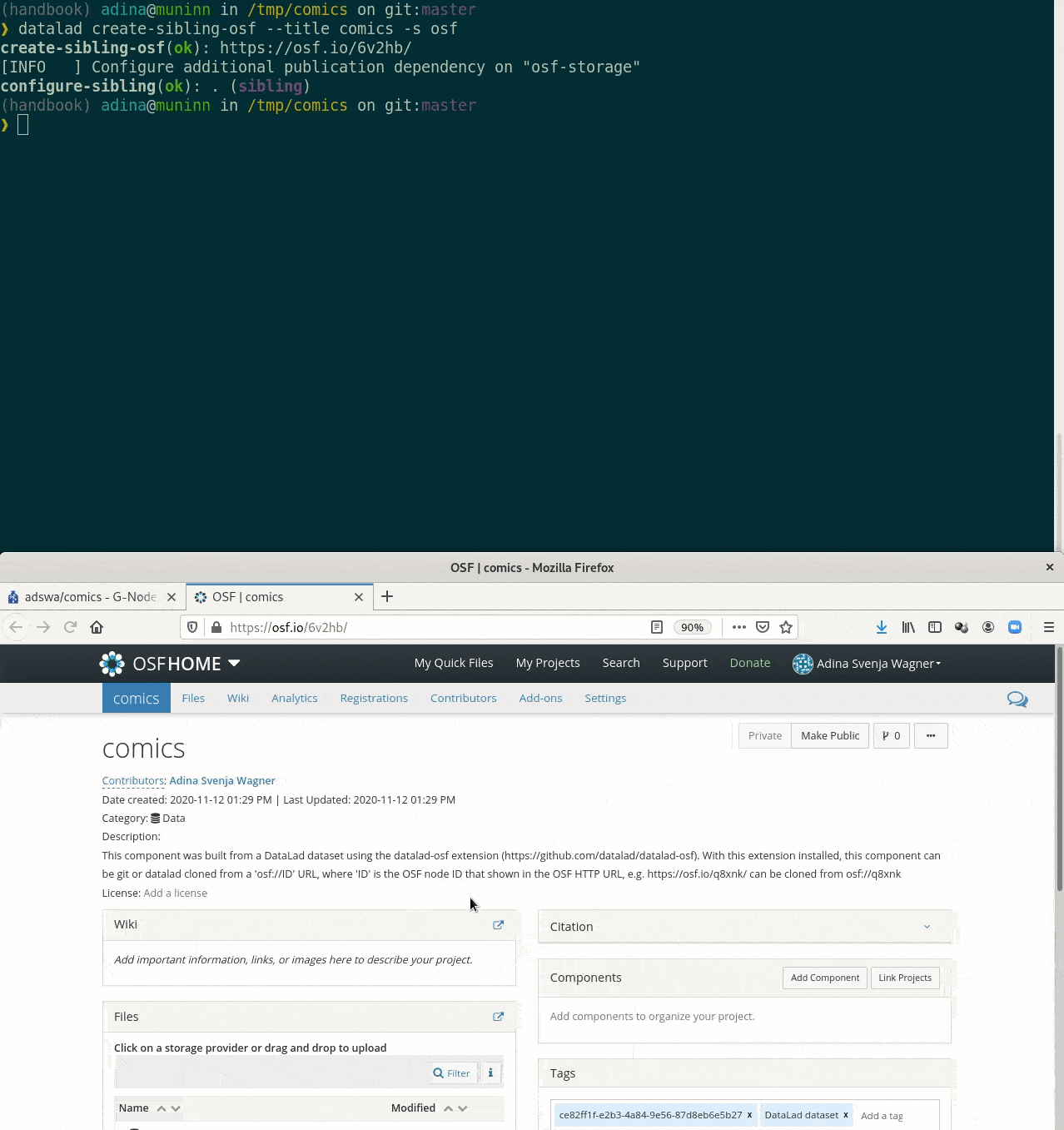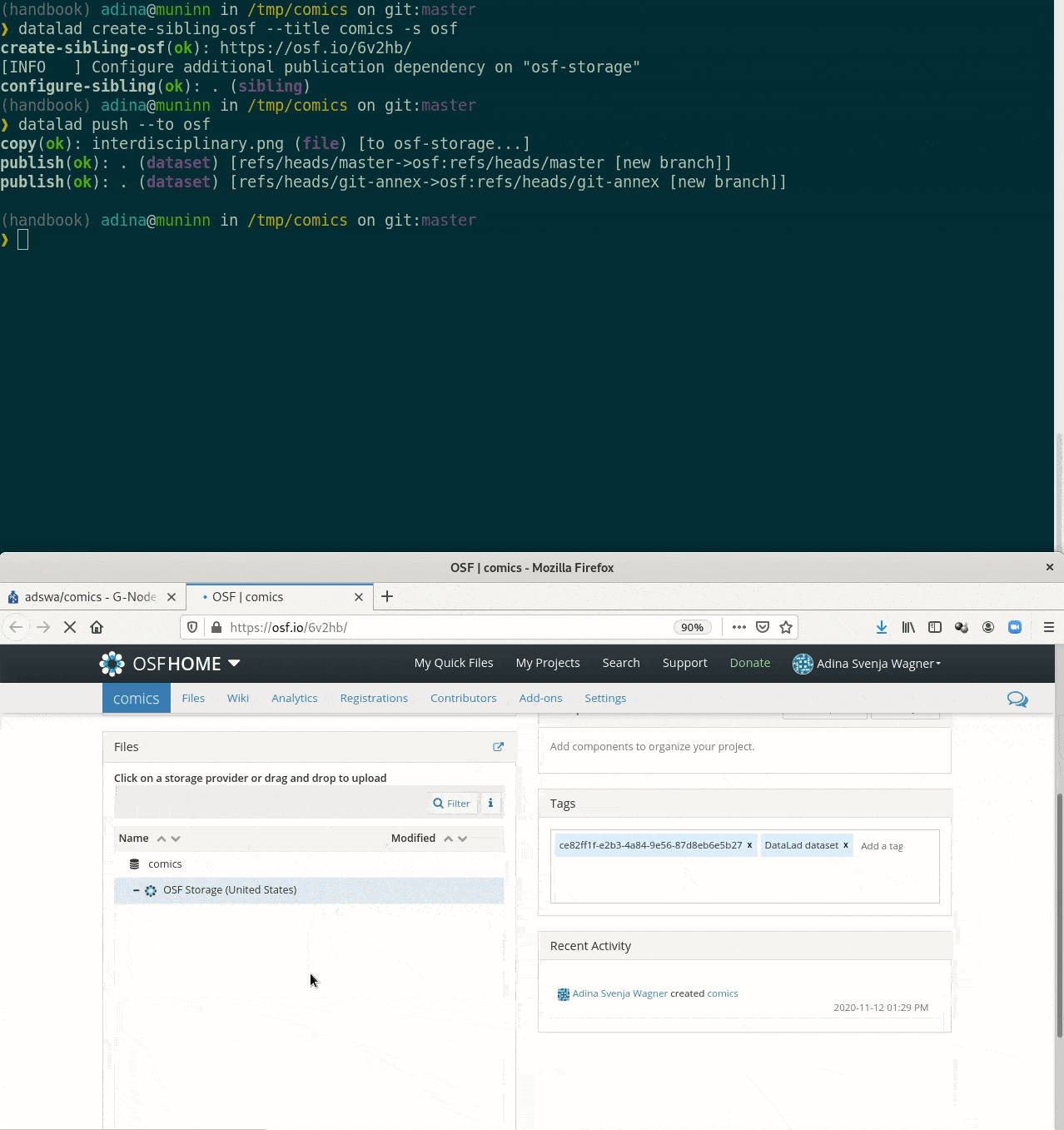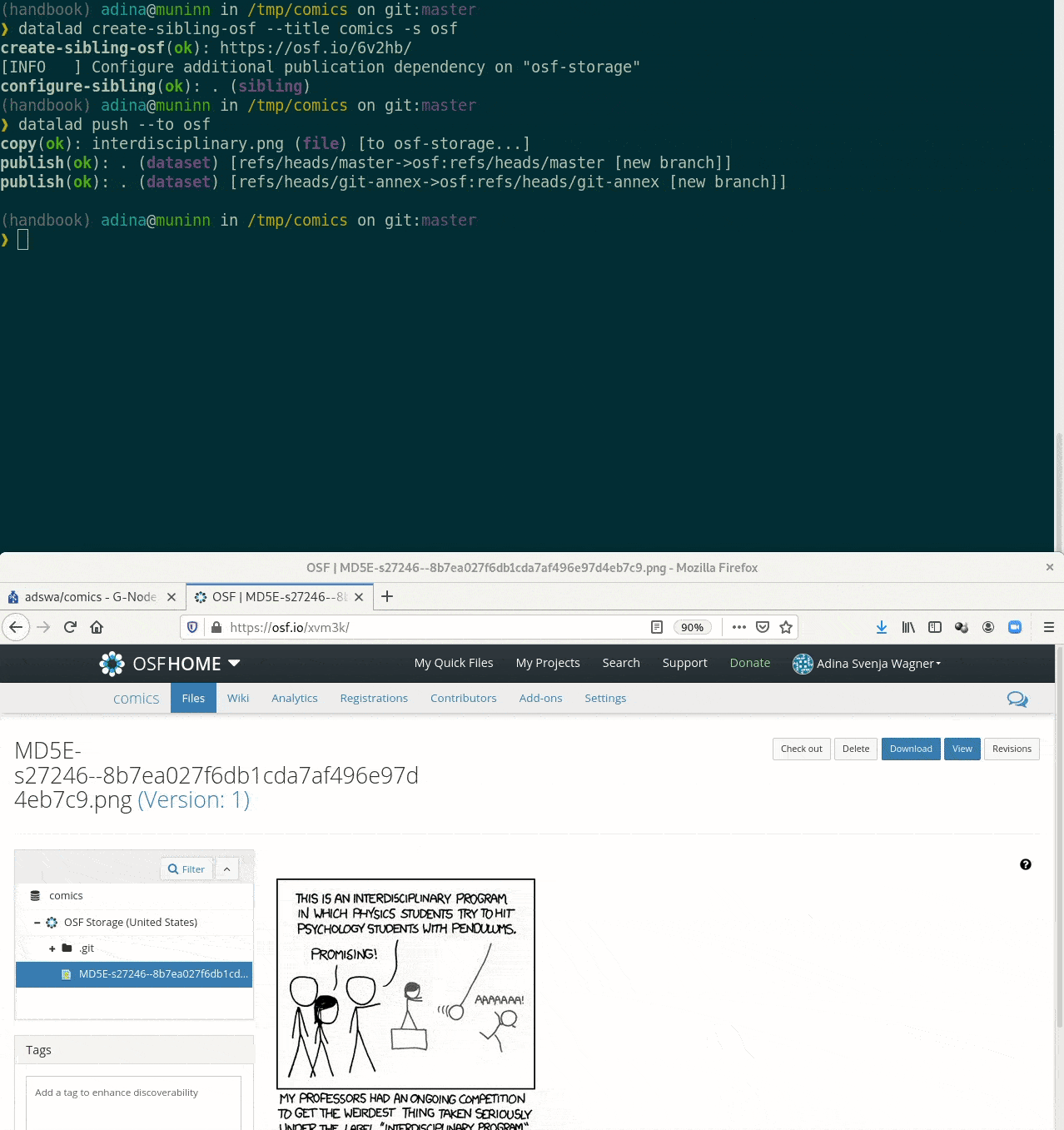
Cloning DataLad datasets
How does cloning dataset feel like for a consumer?
Cloning DataLad datasets
How does cloning dataset feel like for a consumer?
Cloning DataLad datasets
How does cloning dataset feel like for a consumer?
Cloning DataLad datasets
Let's take a look at the special cases: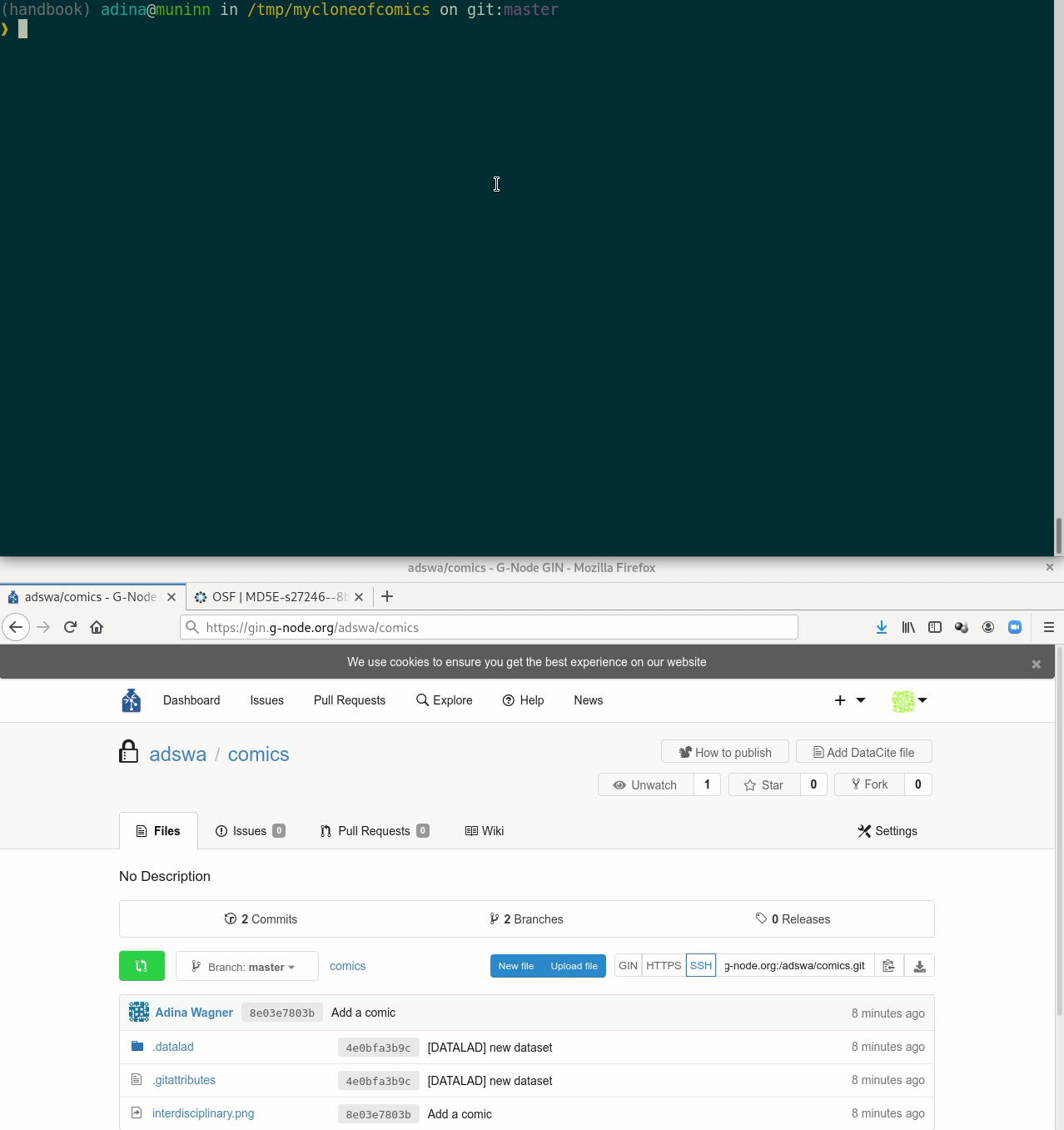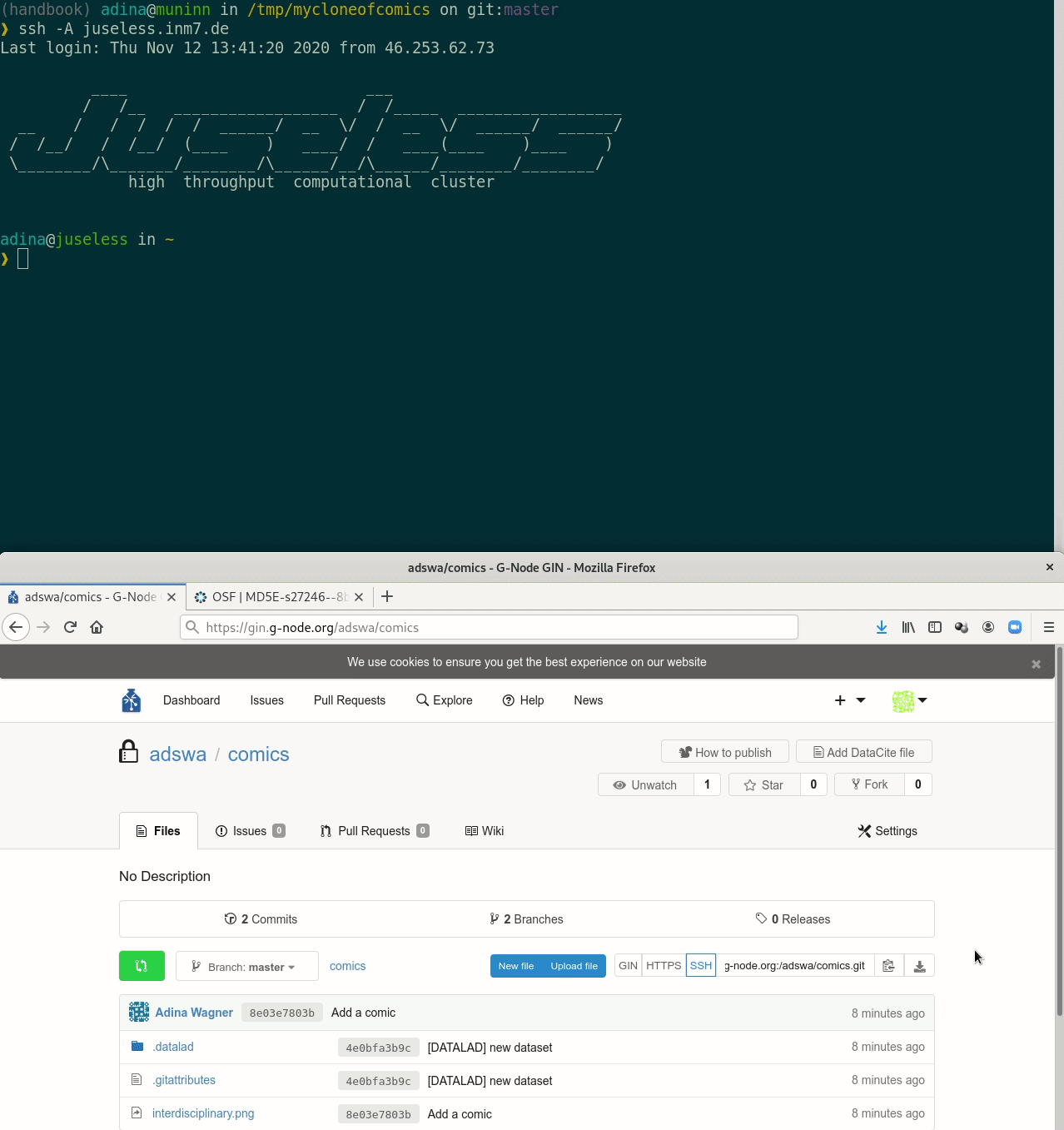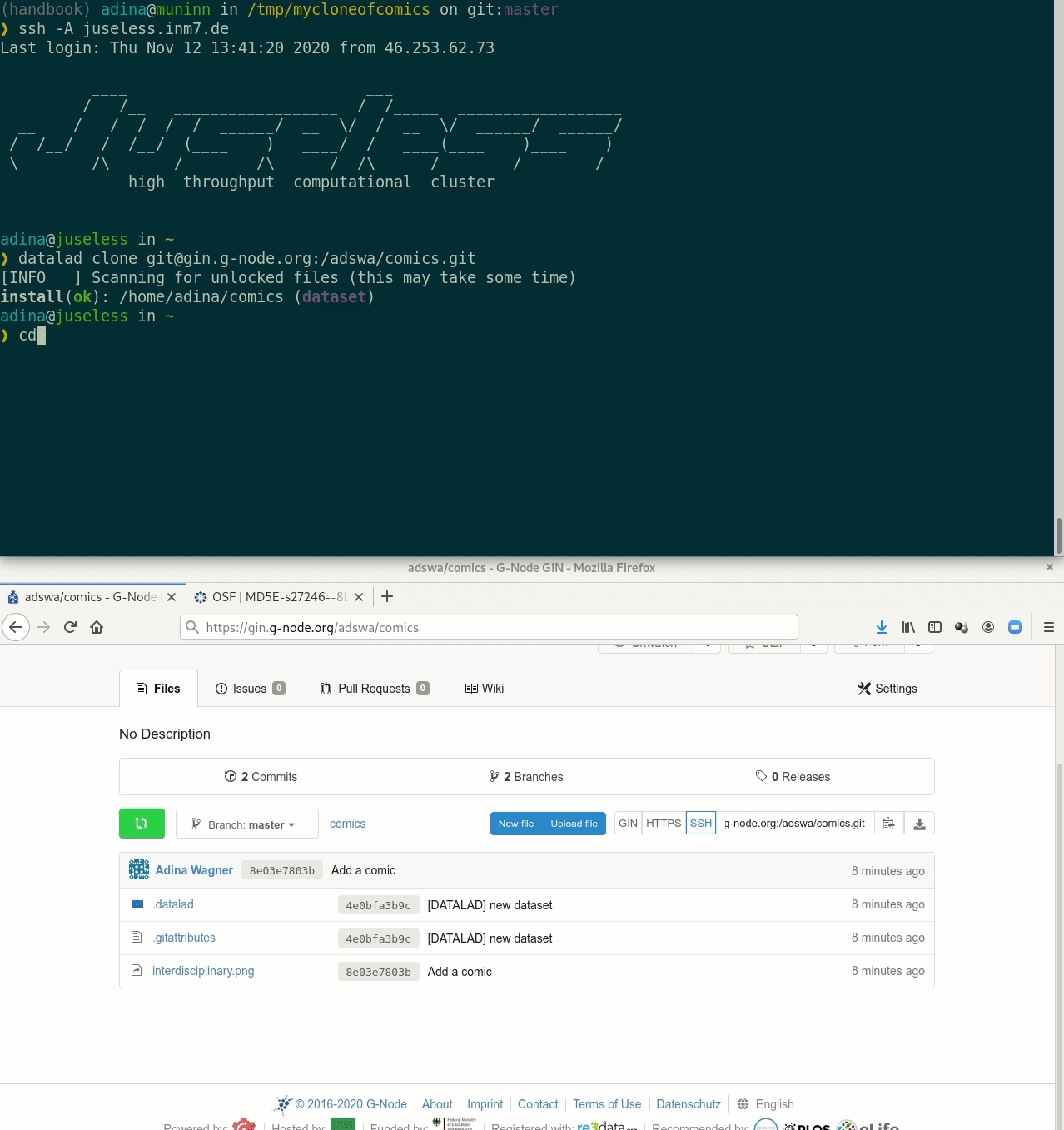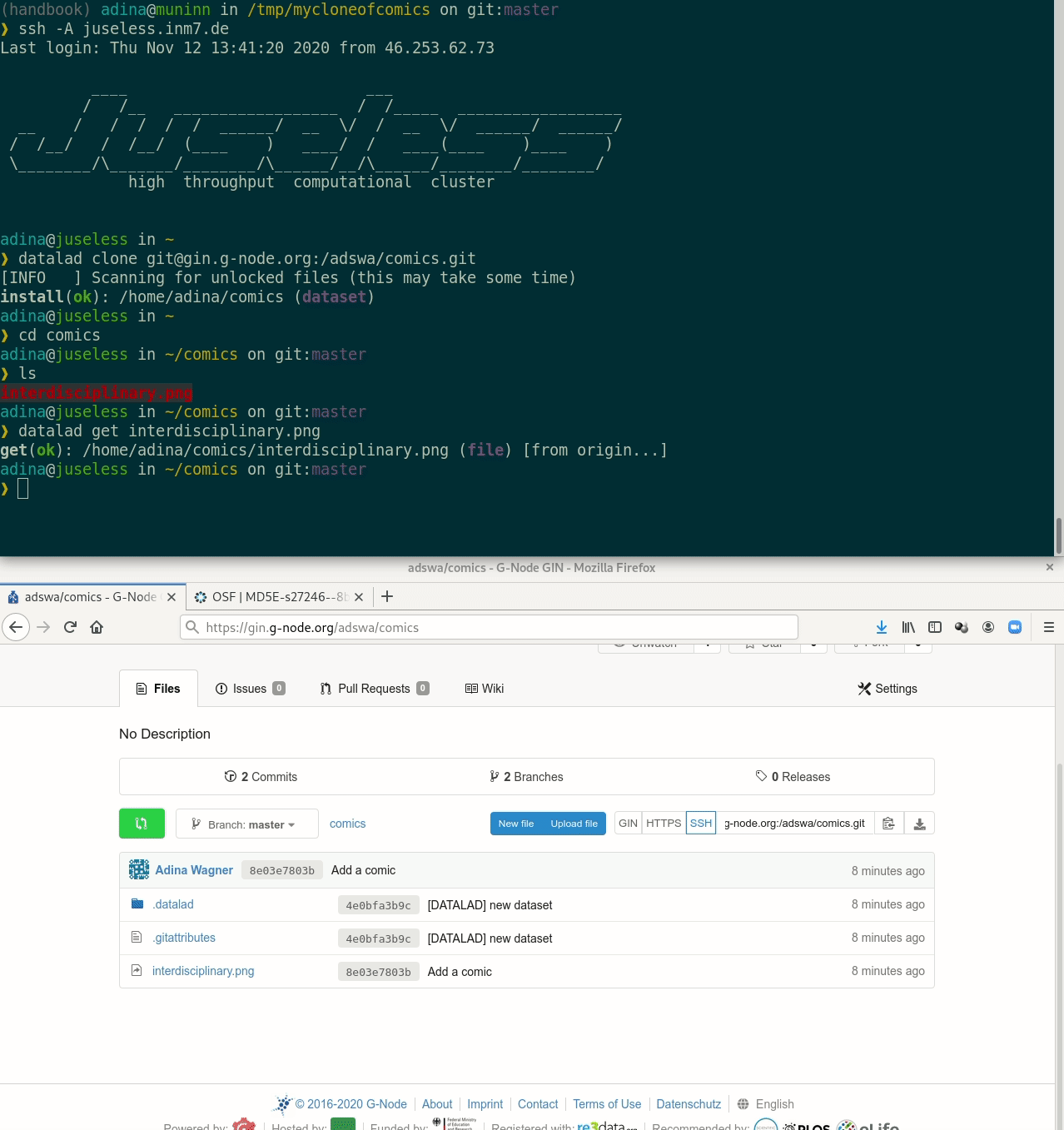
Cloning DataLad datasets
Let's take a look at the special cases: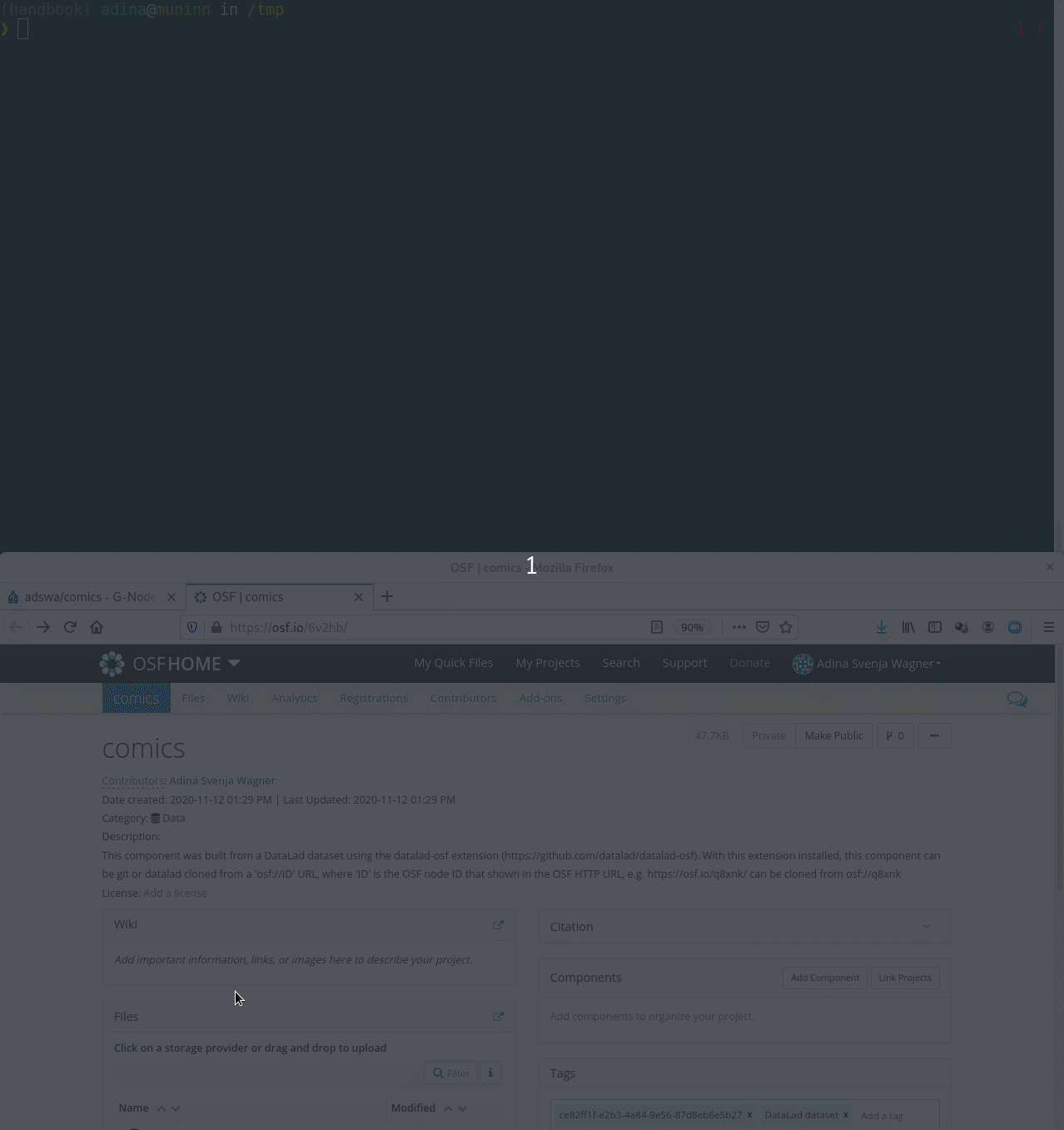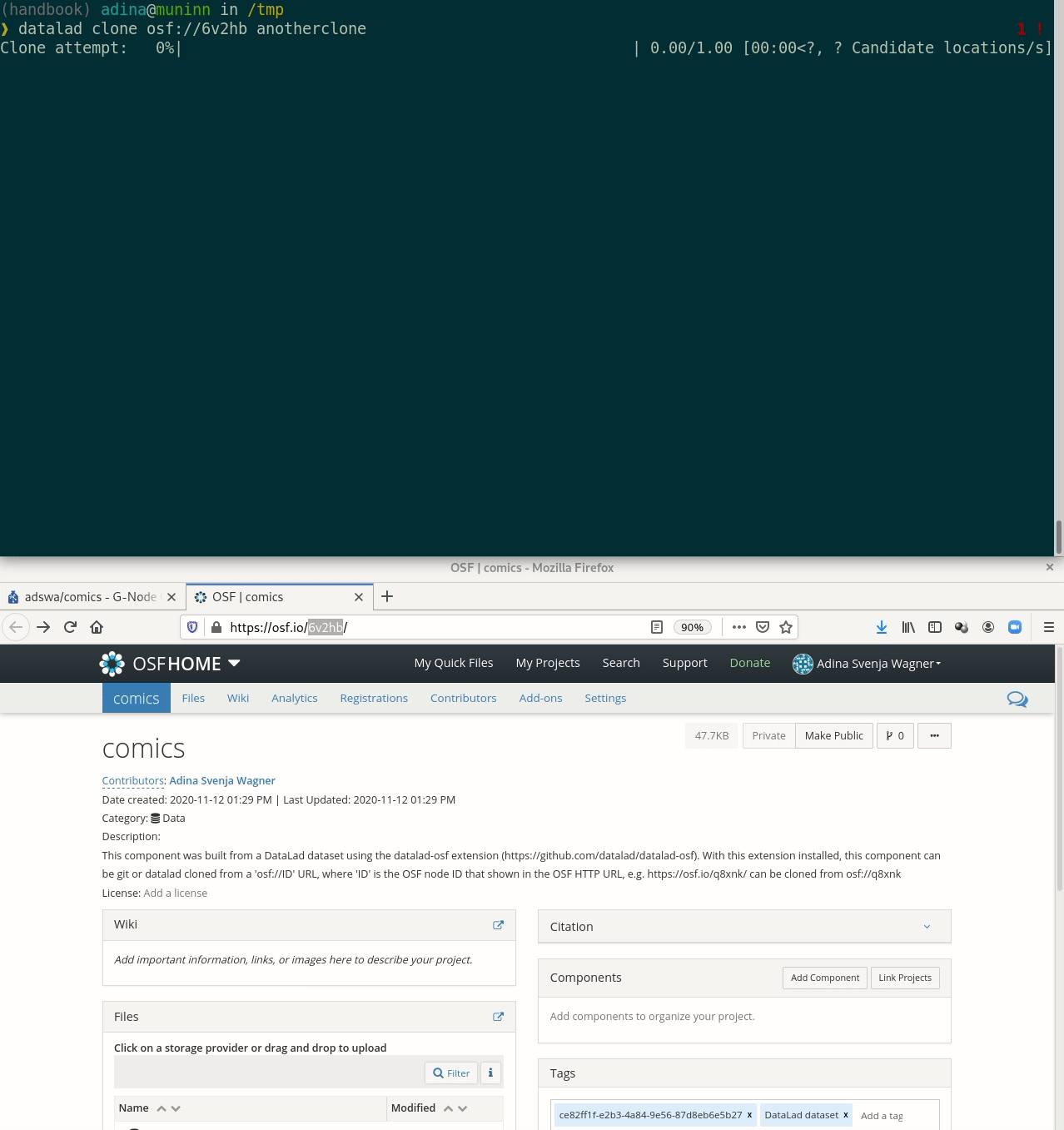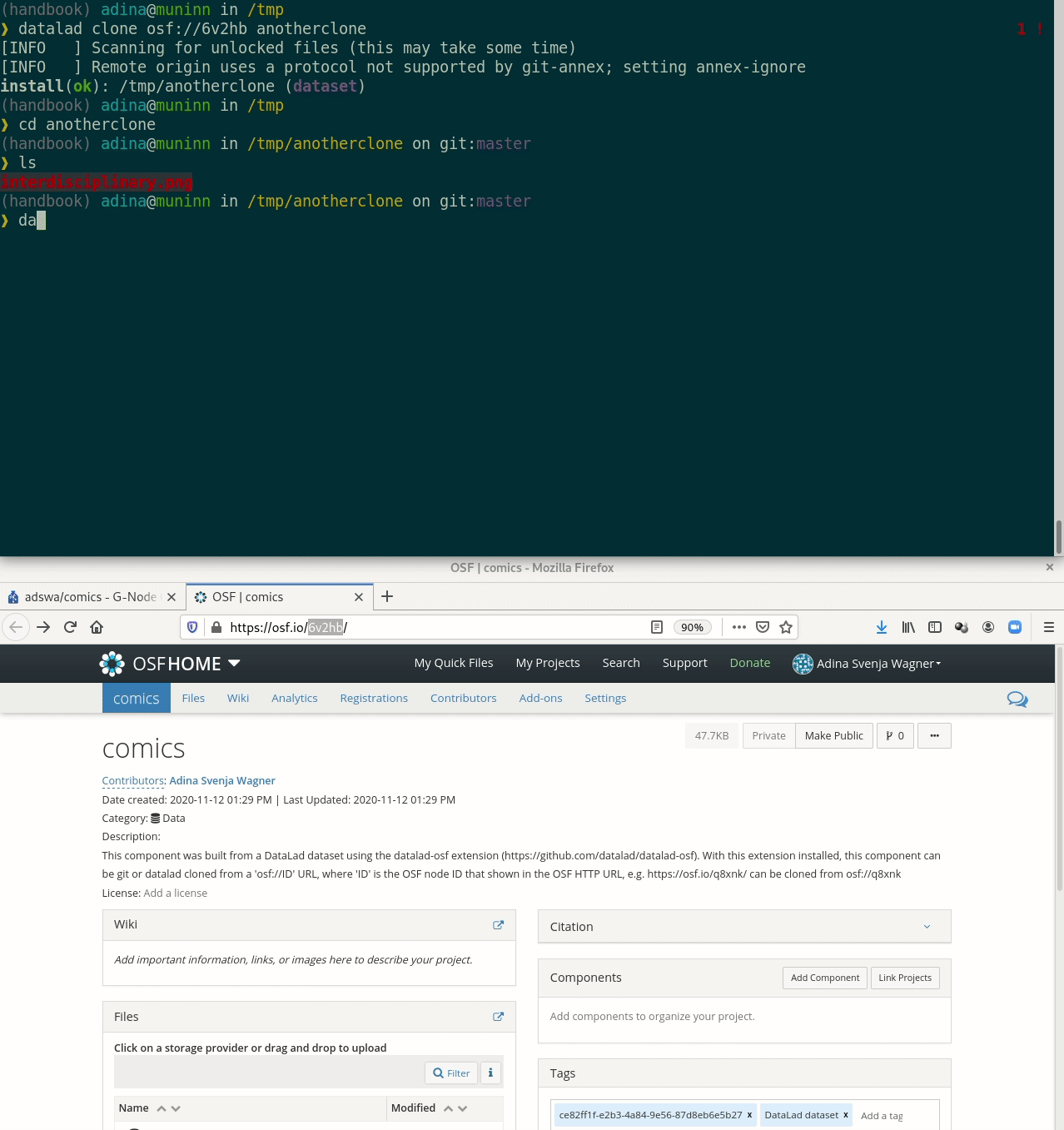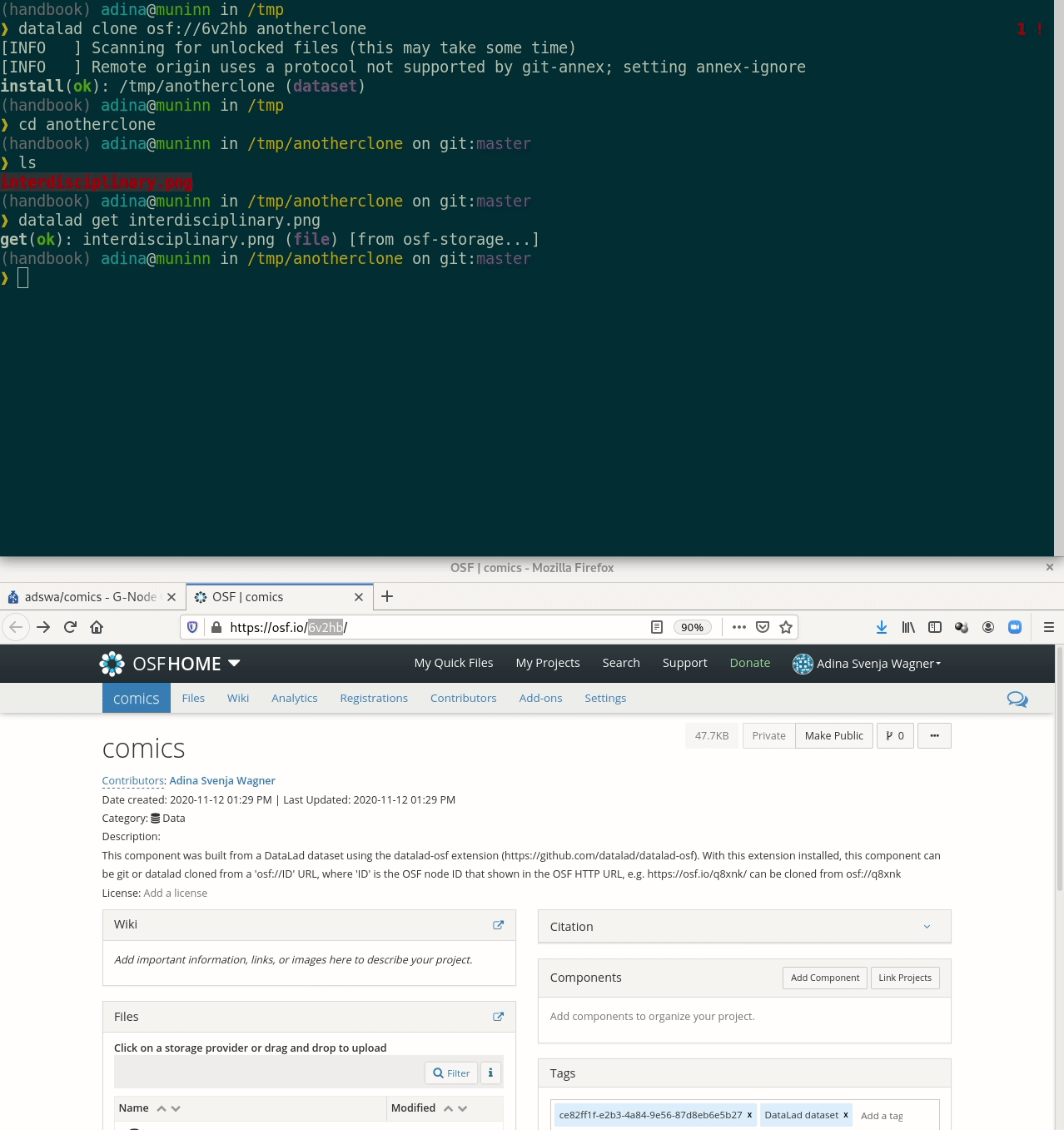
Data sharing using Seafile / Keeper

More info: DataLad Handbook chapter on Third party infrastructure
Keeper (Seafile): A flexible DataLad sibling
https://keeper.mpdl.mpg.de/Keeper offers 1TB flexible storage to all Max Planck employees *
* Even if you end up not using DataLad, you might want to check Keeper out and get those 1TB of storage space!
* Data are stored on servers of the Max Planck Society - your data protection officer will be pleased!
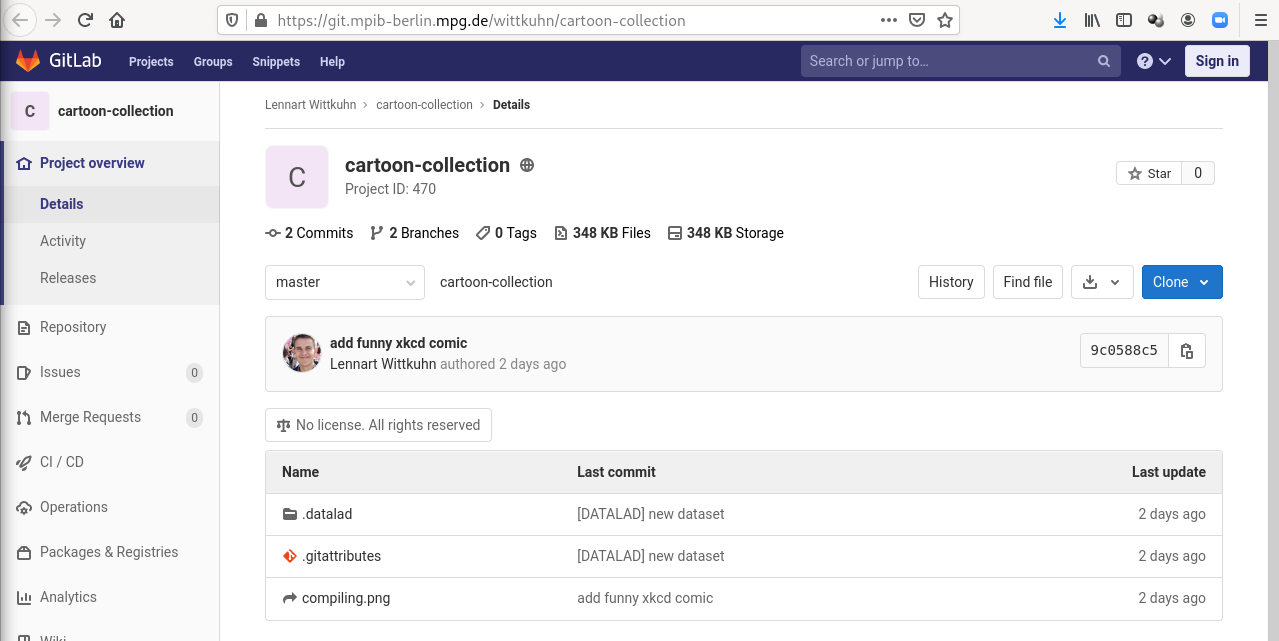
Creating a remote repository
On GitLab (here, of the MPIB) ...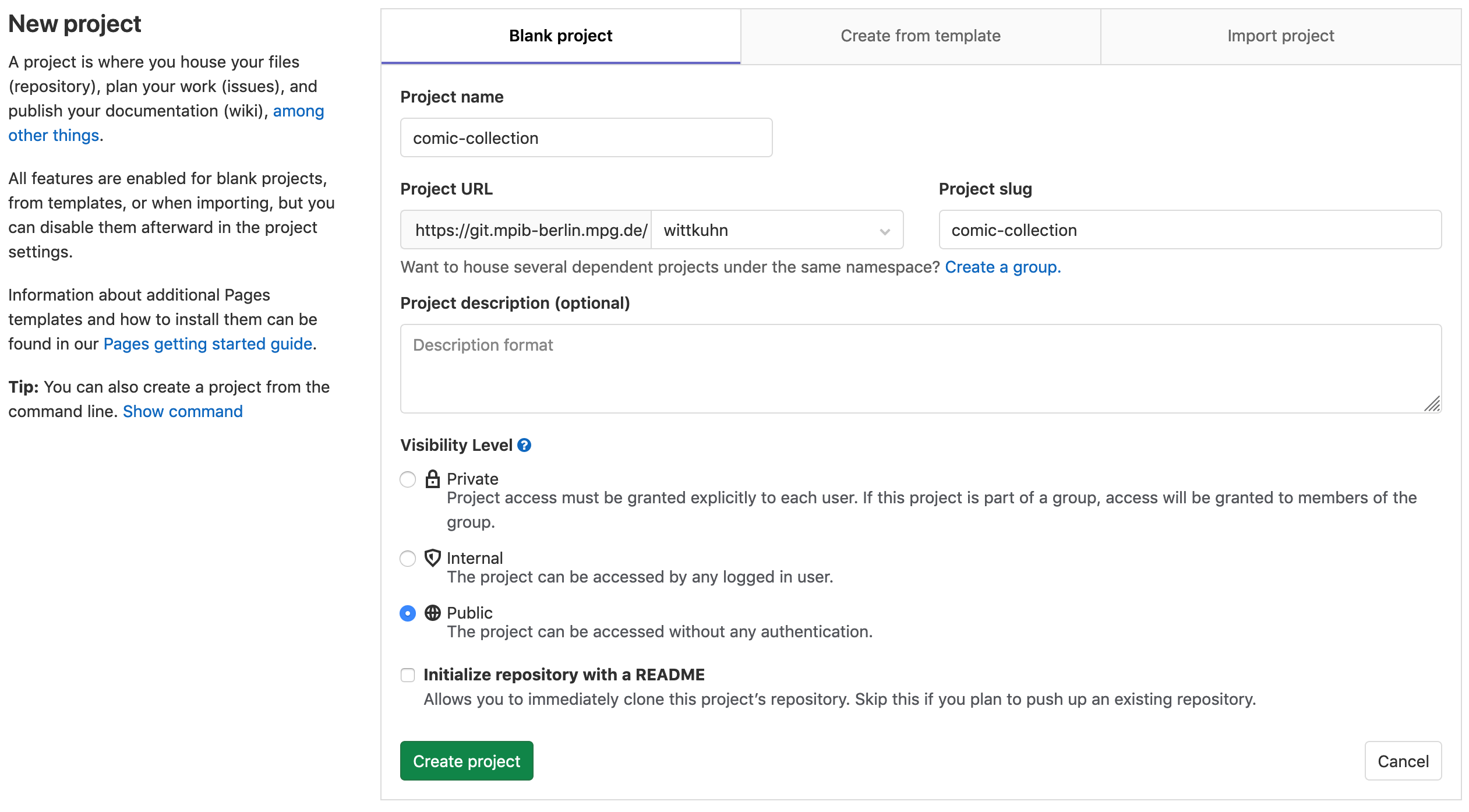
Creating a remote repository
... or on GitHub: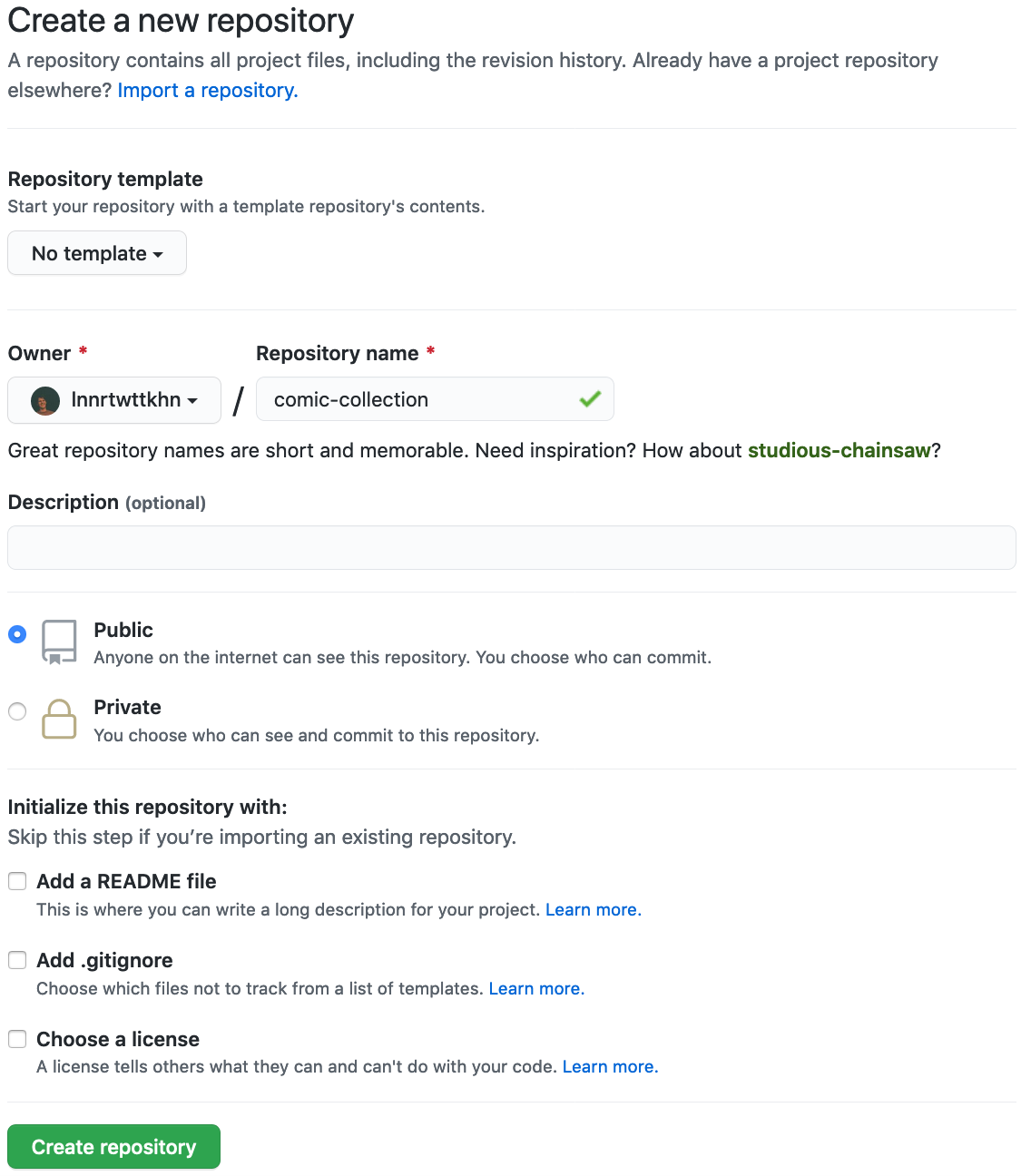
Our comic collection is published!

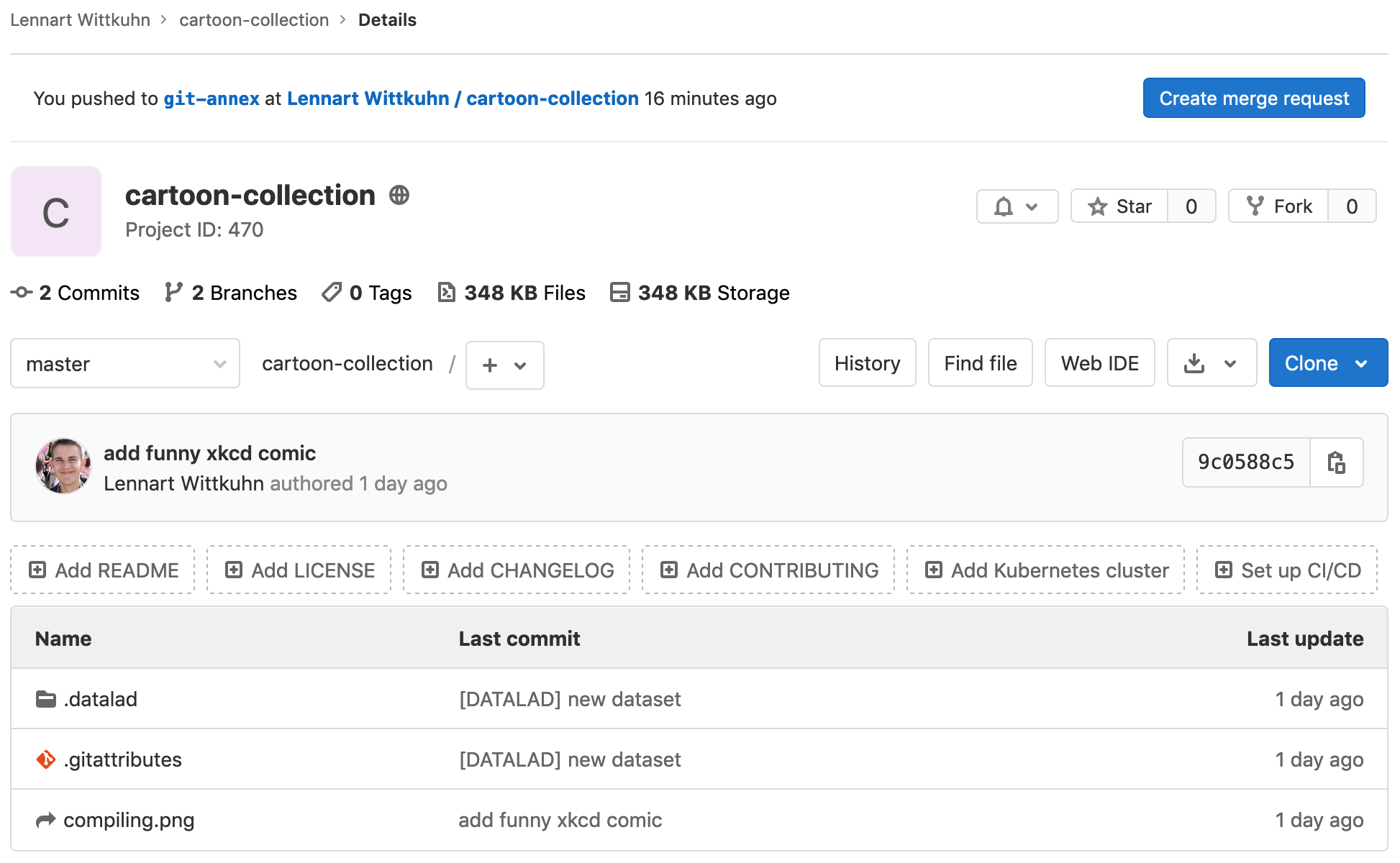
... will allow them to access the annexed contents of your dataset!
(after they successfully configured the seafile rclone special remote)
$ datalad siblings -d "/Users/wittkuhn/Desktop/cartoon-collection" enable -s seafile
.: seafile(?) [git]
$ datalad siblings # just checking if all siblings are configured
.: here(+) [git]
.: seafile(+) [rclone]
.: origin(-) [https://git.mpib-berlin.mpg.de/wittkuhn/cartoon-collection.git (git)]
$ datalad get compiling.png
get(ok): compiling.png (file) [from seafile...]

🎉

But wait... I also know cool comics!
From data sharing to collaboration
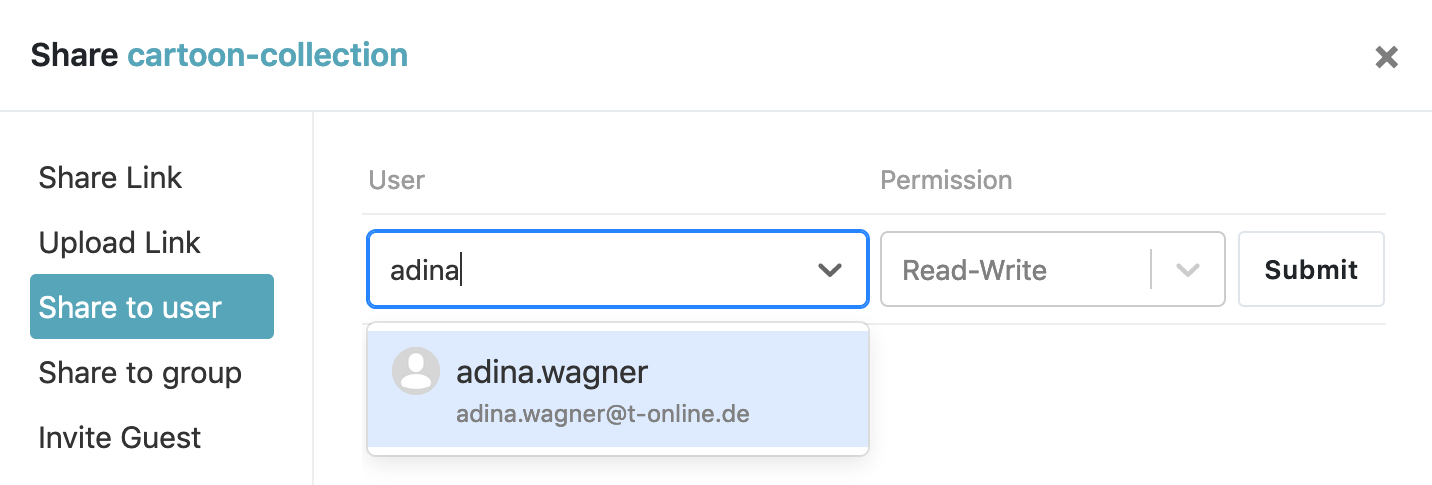
Add a collaborator on GitLab
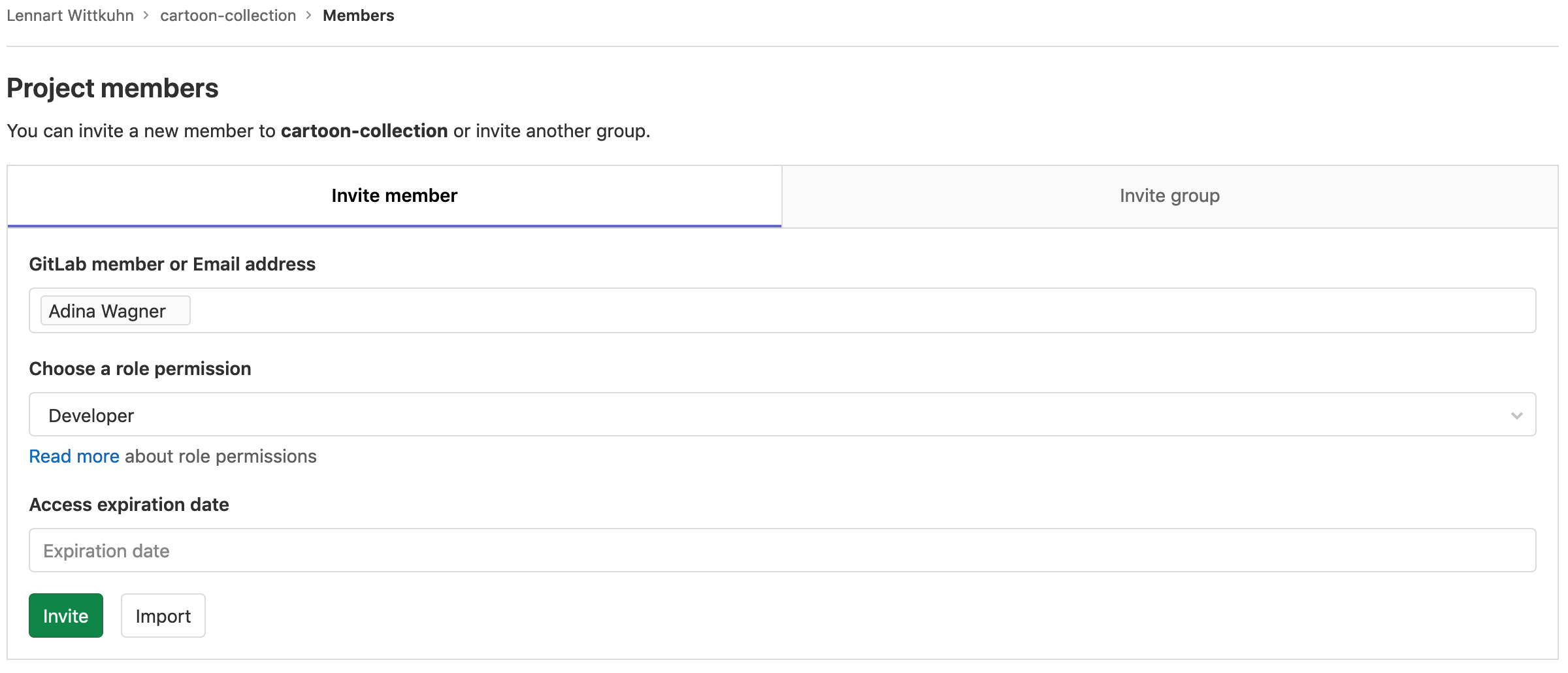 And don't forget to add your collaborators to your Seafile / Keeper library!
And don't forget to add your collaborators to your Seafile / Keeper library!
Collaboration!
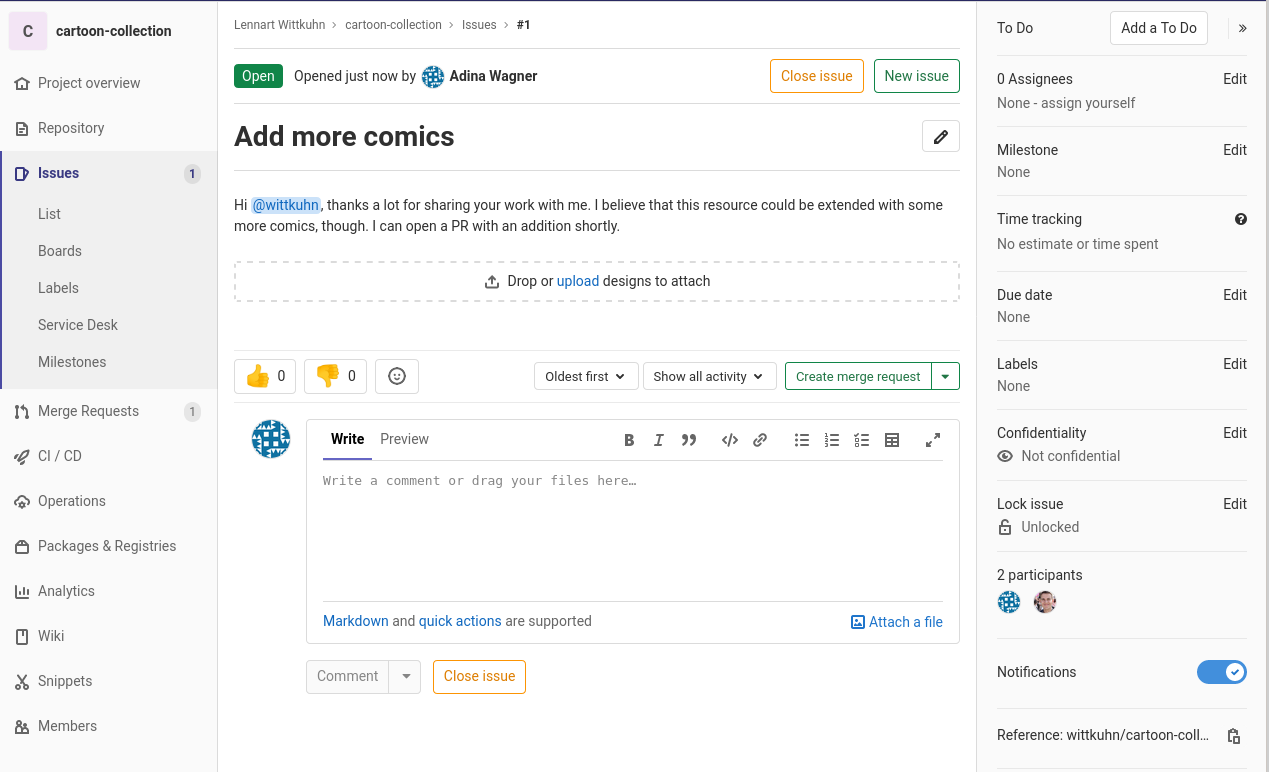
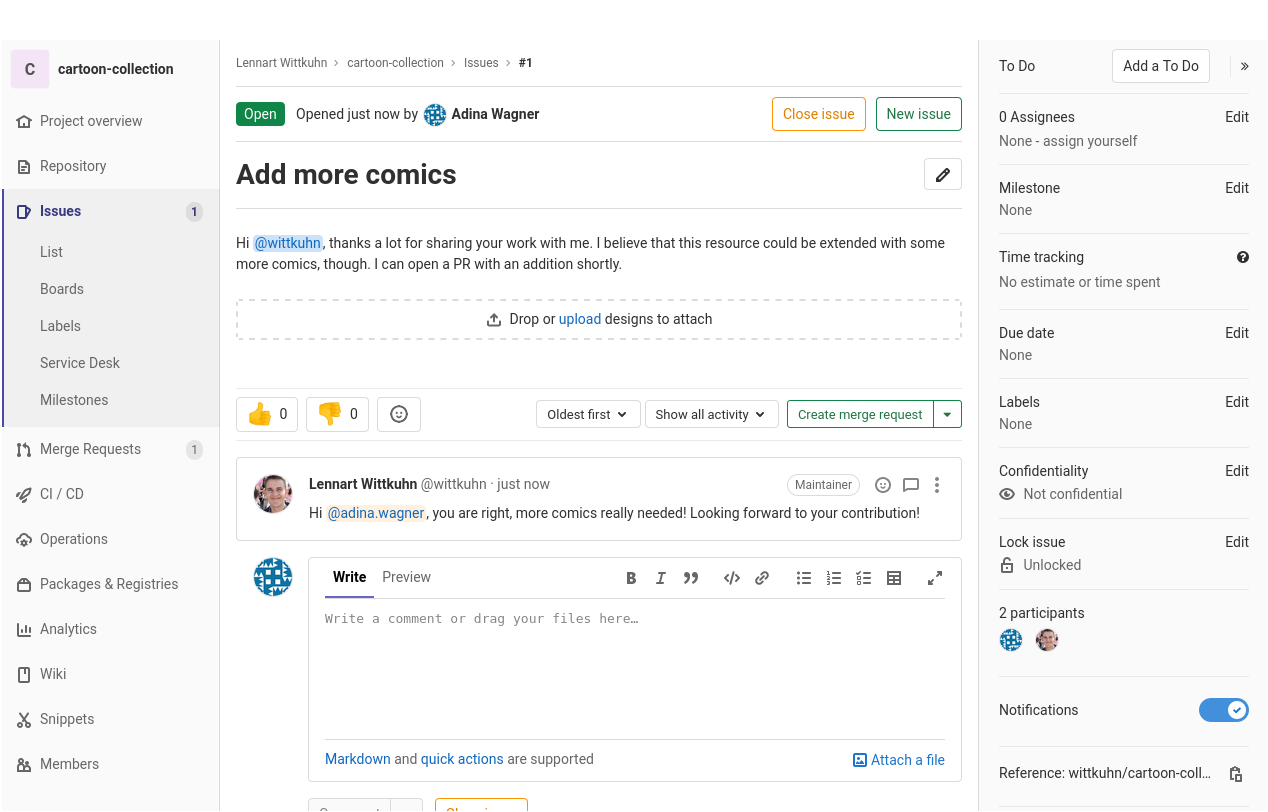
Typical collaborative workflow:- Optional: Create an issue
- It is good practice to let you collaborators know what you are working
on. Creating an issue on GitLab is a good way to give them a heads-up
and discuss plans
Collaboration!
Typical collaborative workflow:- Optional: Create an issue
- It is good practice to let you collaborators know what you are working
on. Creating an issue on GitLab is a good way to give them a heads-up
and discuss plans
Collaboration!
- Step 1: Create a new branch in your dataset
- It is good practice to develop a new
feature/add data/extend code/... in a new branch
$ git checkout -b morecomics
Switched to a new branch 'morecomics'Collaboration!
- Step 2: Make a change, and save it
$ wget https://imgs.xkcd.com/comics/interdisciplinary.png
--2020-11-15 12:23:22-- https://imgs.xkcd.com/comics/interdisciplinary.png
Resolving imgs.xkcd.com (imgs.xkcd.com)... 2a04:4e42:1b::67, 151.101.112.67
Connecting to imgs.xkcd.com (imgs.xkcd.com)|2a04:4e42:1b::67|:443... connected.
HTTP request sent, awaiting response... 200 OK
Length: 27246 (27K) [image/png]
Saving to: ‘interdisciplinary.png’
interdisciplinary.p 100%[===================>] 26.61K --.-KB/s in 0.001s
2020-11-15 12:23:23 (29.4 MB/s) - ‘interdisciplinary.png’ saved [27246/27246]
$ datalad save -m "Add another fun comic" interdisciplinary.png
add(ok): interdisciplinary.png (file)
save(ok): . (dataset)
action summary:
add (ok: 1)
save (ok: 1)Collaboration!
- Optional: Configure a publication dependency to seafile
- With a publication dependency,
datalad push pushes
annexed data to seafile, and the rest to GitLab$ datalad siblings
.: here(+) [git]
.: origin(-) [https://git.mpib-berlin.mpg.de/wittkuhn/cartoon-collection.git (git)]
.: seafile(+) [rclone]
$ git config --local remote.origin.datalad-publish-depends seafileThis translates to: When pushing anything to the sibling/remote "origin", push changes to the sibling "seafile" first!
Collaboration!
Collaboration!
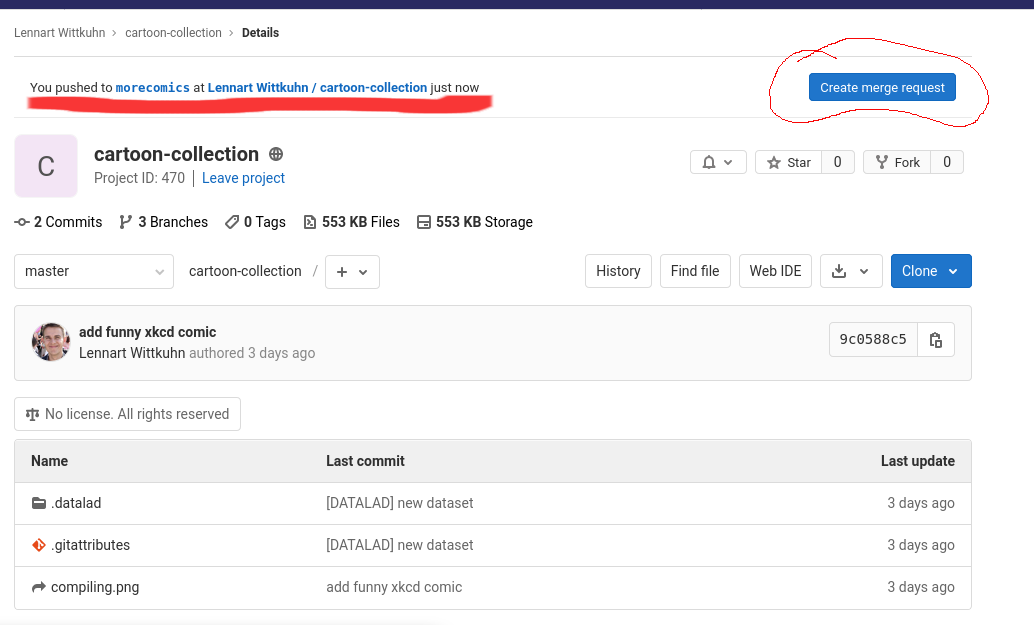
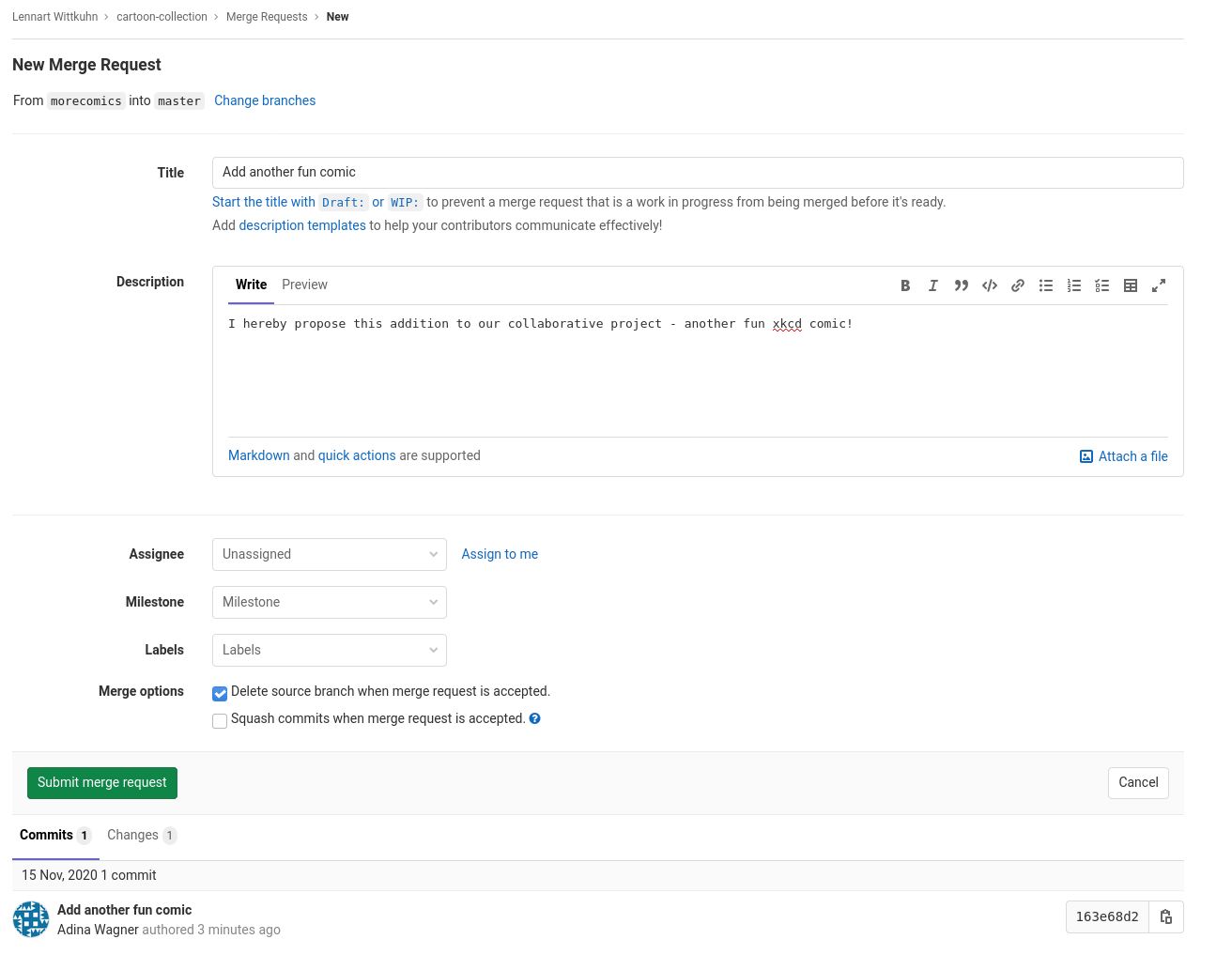
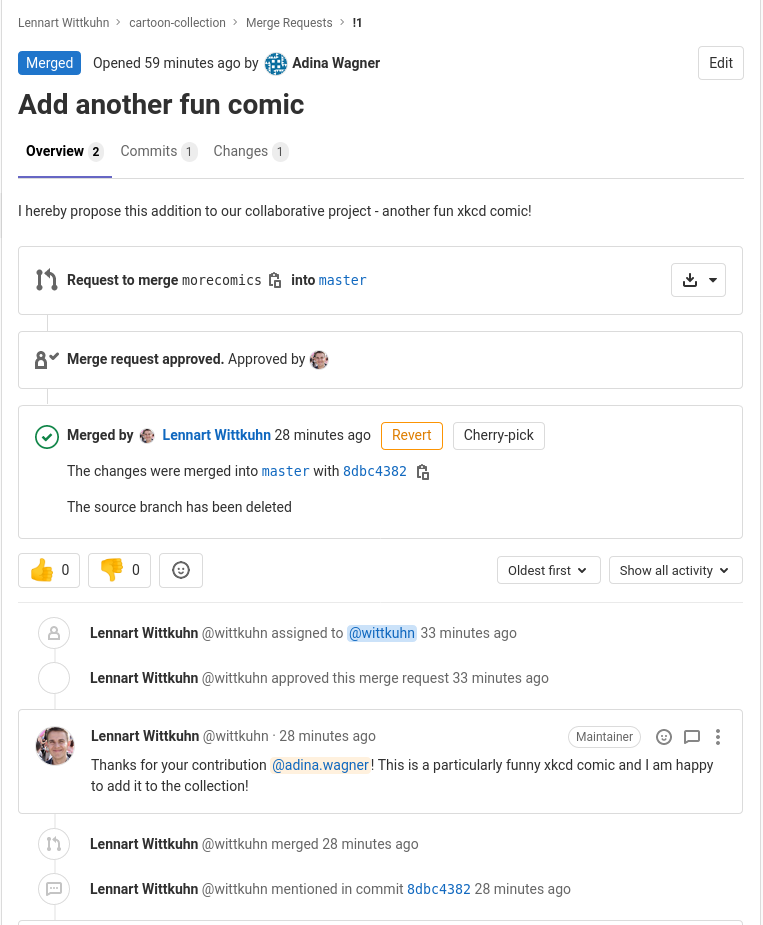
- Step 4: Push your change and create a merge request
$ datalad push --to origin
Push to 'origin': 25%|████▎ | 1.00/4.00 [00:00<00:00, 11.6k Steps/s]
Username for 'https://git.mpib-berlin.mpg.de': adina.wagner
Password for 'https://adina.wagner@git.mpib-berlin.mpg.de':
copy(ok): interdisciplinary.png (file) [to seafile...]
Update availability for 'origin': 75%|▊| 3.00/4.00 [00:00<00:00, 7.48k Steps/s]
Username for 'https://git.mpib-berlin.mpg.de': adina.wagner<00:01, 1.31 Steps/s]
Password for 'https://adina.wagner@git.mpib-berlin.mpg.de':
publish(ok): . (dataset) [refs/heads/git-annex->origin:refs/heads/git-annex 048e2c4..595f30a]
publish(ok): . (dataset) [refs/heads/morecomics->origin:refs/heads/morecomics [new branch]]
Collaboration!
- Step 4: Push your change and create a merge request
Collaboration!
- Step 4: Push your change and create a merge request
Collaboration!
- Step 4: Push your change and create a merge request

But, phewww, isn't there an "easier" way?
"My collaborators don't want to deal with DataLad" 😢
Don't worry, just let them download the dataset:
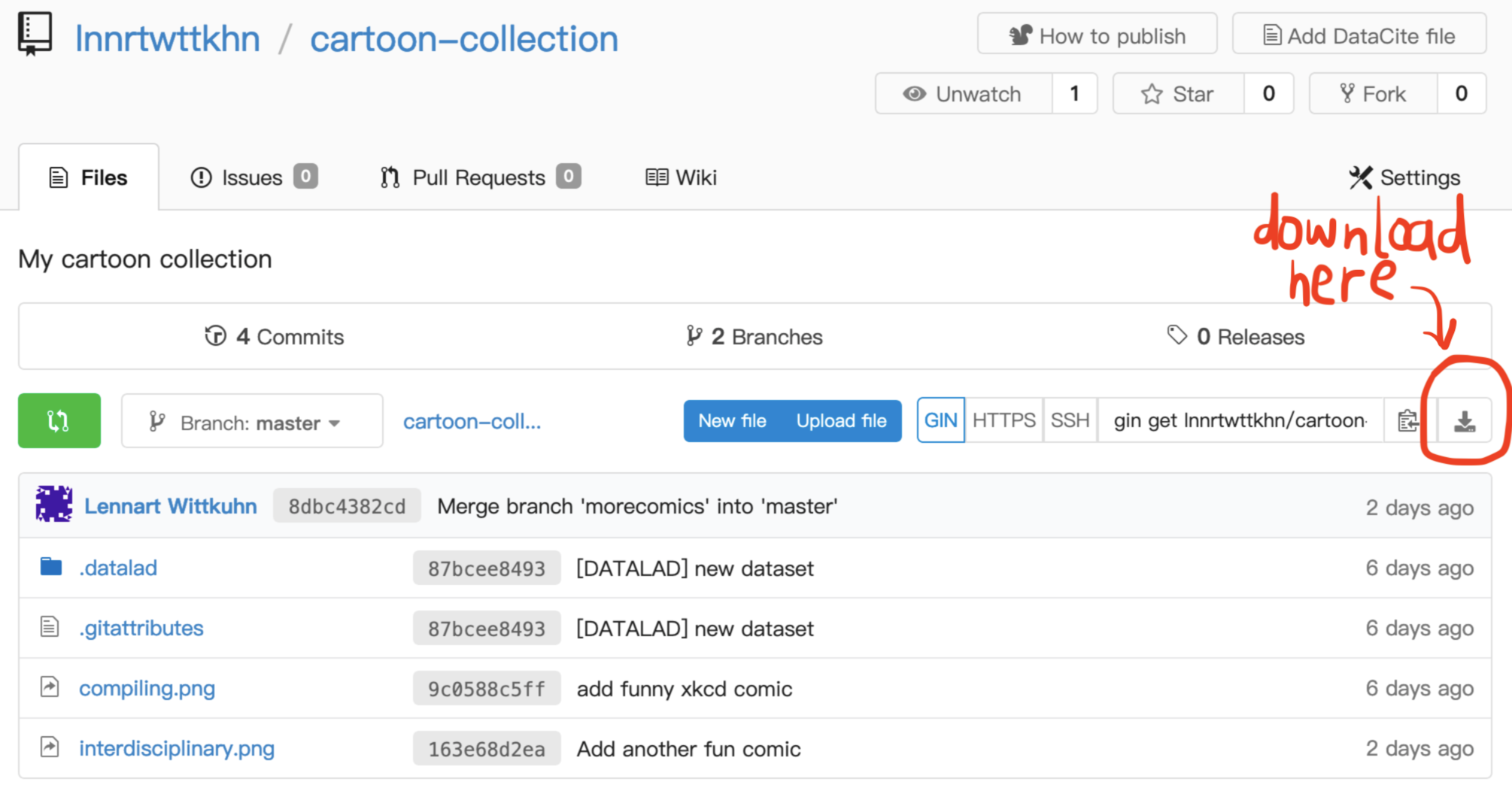
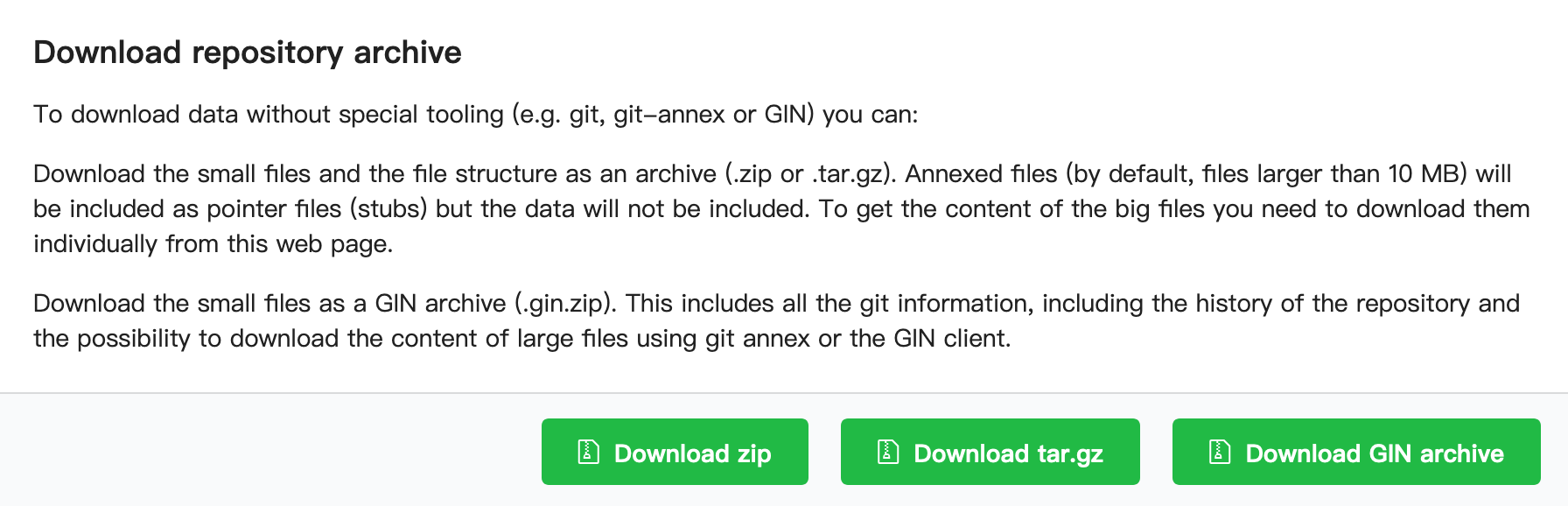
But tell them they are missing out on learning an awesome tool! 😜
(Admittedly, if you publish publicly, not everyone will consume your dataset through DataLad, so the download option is nice to have!)
Collaboration!
Overview of a typical collaborative workflow:
- Optional: Create an issue
- Step 1: Create a new branch in your dataset
- Step 2: Make a change, and save it
- Step 3: (optional) Configure a publication dependency
- Step 4: Push your change and create a merge request
- It is good practice to let you collaborators know what you are working
on. Creating an issue on GitLab is a good way to give them a heads-up
and discuss plans
- It is good practice to develop a new feature/data point/code in a
new branch
- With a publication dependency,
datalad push pushes
annexed data to a special remote, and the rest to GitLab